correspSearch knackt 400.000-Marke – mit Helmina von Chézy
Der Webservice correspSearch, der historische Briefe durchsuchbar macht und vernetzt, hat einen wichtigen Meilenstein erreicht. Mit der jüngsten Integration der Briefe an Helmina von Chézy, die durch ein Explorationsprojekt an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) ermöglicht wurde, weist die Plattform nun mehr als 400.000 Metadatensätze von edierten oder wissenschaftlich erschlossenen Briefen nach.

Initiiert von der BBAW-Arbeitsgruppe „Gender & Data“ und mit institutioneller Unterstützung der Akademie wird seit 2025 an der Erschließung der Korrespondenzen in Helmina von Chézys Nachlass im Akademiearchiv gearbeitet (Mitwirkende s. u.). Innerhalb von acht Monaten wurde die umfangreiche Korrespondenz von rund 3.500 Briefen mit Unterstützung von TELOTA und unter Nutzung des CMIF Creators erfasst und für die Aufnahme in correspSearch vorbereitet. Etwa 2.000 Briefe wurden an Chézy gerichtet und knapp 1.400 von ihr verfasst. Erstere sind nun freigeschaltet, die Briefe von Chézy selbst werden in Kürze ebenfalls integriert. Zukünftig sollen die Informationen auch zurück in das Findbuch des BBAW-Archivs fließen, um die Nutzung der Bestände vor Ort zu verbessern.
Die Aufnahme der Briefe in correspSearch stellt sicher, dass die Daten standardisiert und langfristig recherchierbar und für die Forschung nutzbar sind. Auch weitere Datenlieferungen trugen dazu bei, die Marke von 400.000 Briefversionen zu erreichen, u.a. der Briefwechsel zwischen Heinrich Mann und Inés Schmied, die Korrespondenz Wilhelm Wieprechts, Frank Wedekinds Korrespondenz digital, der Briefwechsel von Alice und Ludwig Klein, die Historisch-Kritische Ausgabe der Briefe von Goethe oder die Korrespondenz von Else Lasker-Schüler.
Helmina von Chézys Korrespondenznetzwerk
Helmina von Chézy (1783–1856) war als Schriftstellerin, Journalistin und Intellektuelle in vielfältige Netzwerke eingebunden. Mit rund 20 Jahren ging sie nach Paris und verbrachte dort ein prägendes Jahrzehnt, in dem sie Kontakte zu den Romantikern Dorothea und Friedrich Schlegel knüpfte und journalistisch für französische und deutsche Zeitschriften arbeitete. Ein besonderes Kapitel stellte ihr humanitäres Engagement 1815/16 dar, als sie in Lazaretten in Köln und Namur verwundete Soldaten pflegte. Ihr kritischer Bericht über deren schlechte Behandlung führte zu einer Gefängnisstrafe, vor der sie nach Berlin floh, wo E. T. A. Hoffmann erfolgreich ihre Verteidigung übernahm. Ihre Dresdner Jahre (1817–1823) markierten einen Höhepunkt ihres Schaffens durch die Mitgliedschaft im Dresdner Liederkreis und die Zusammenarbeit mit Carl Maria von Weber am Libretto zur Oper „Euryanthe“.
Helmina von Chézys Korrespondenz bildet den zentralen Bestandteil ihres Nachlasses. Rund 3.500 Briefe dokumentieren ein weitreichendes Netzwerk aus Personen aus Literatur, Kunst, Politik und Verlagswesen. Die Briefe geben Einblick in literarische Arbeitszusammenhänge und soziale Beziehungen und zeigen zugleich die Lebensbedingungen einer Frau, die sich im frühen 19. Jahrhundert in einem überwiegend männlich geprägten kulturellen Umfeld behauptete. Ein nicht unerheblicher Teil der Korrespondenz entfällt auf den Austausch mit Frauen und verweist auf die Bedeutung weiblicher Netzwerke in dieser Zeit.
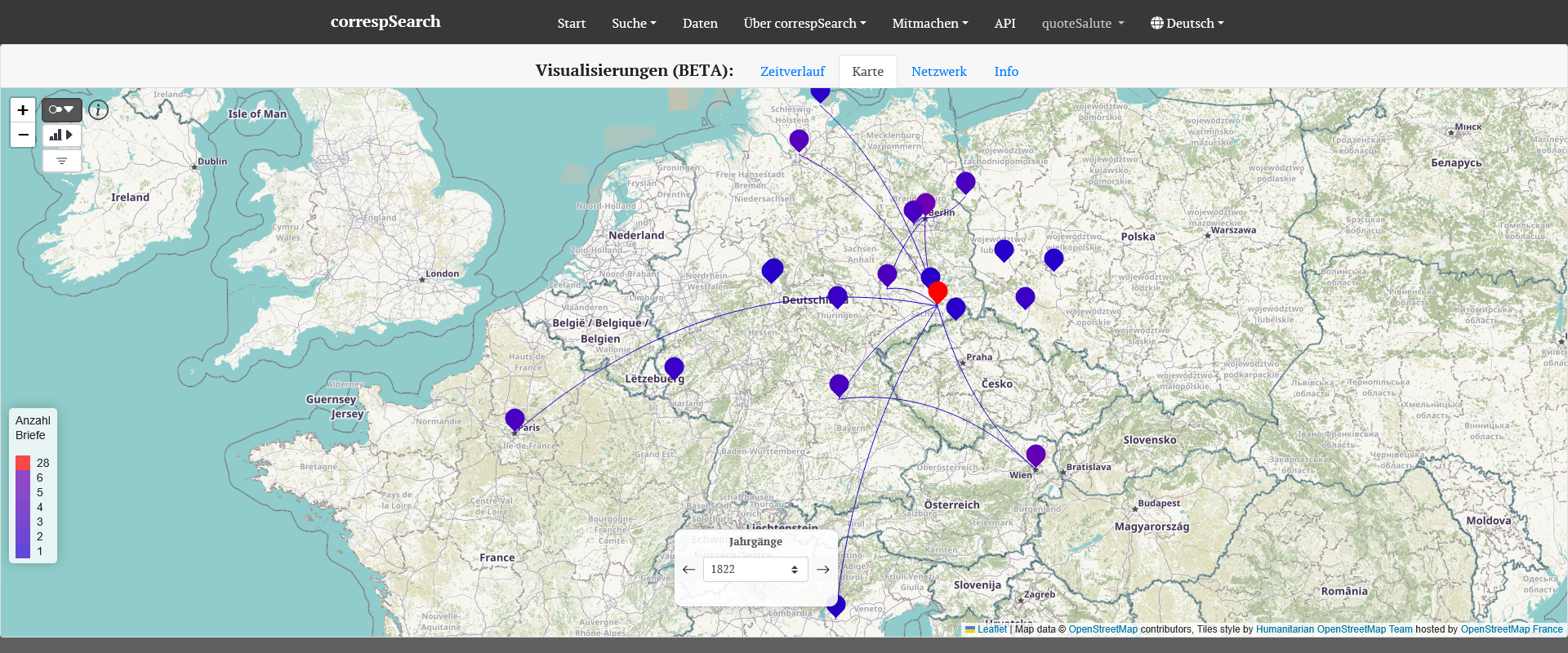
Helmina von Chézys internationales Briefnetzwerk im Jahr 1822 während ihres Aufenthalts in Dresden. [Screenshot der Visualisierung in correspSearch]
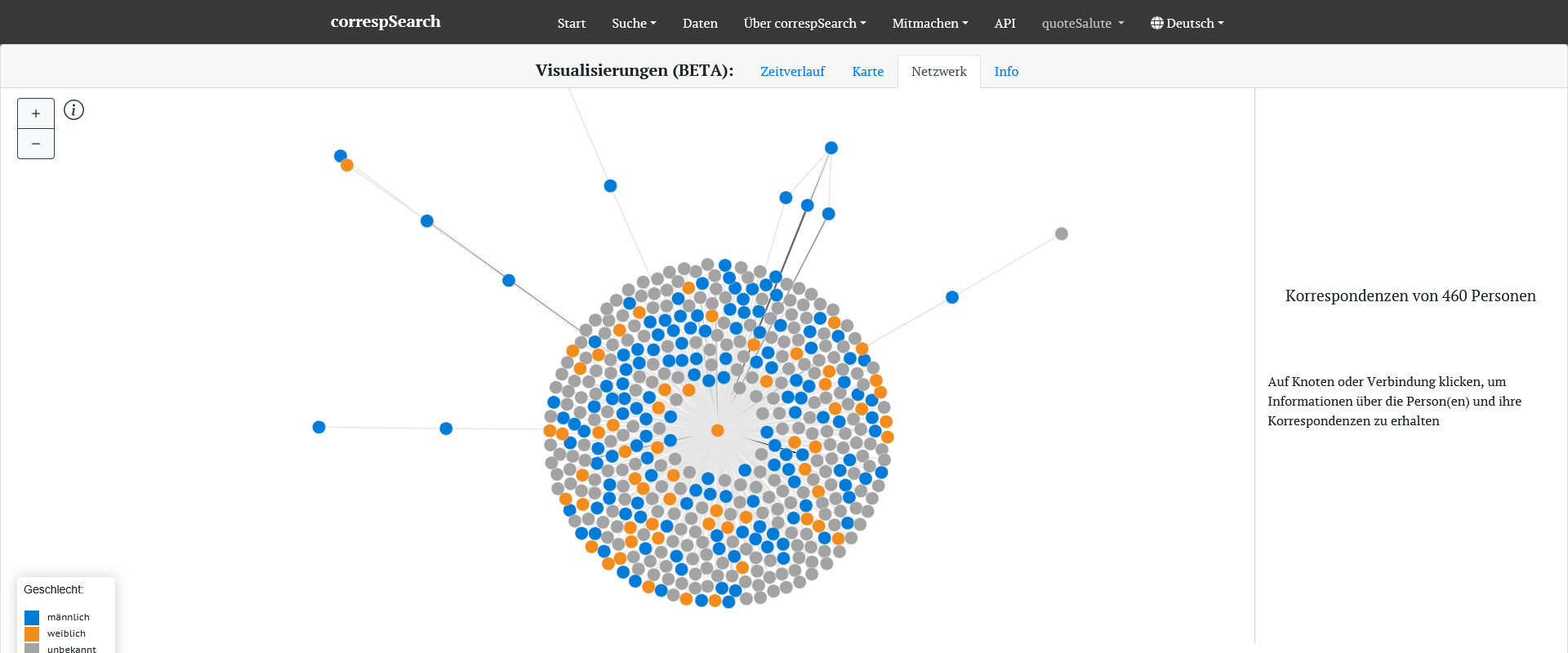
Netzwerk der an Helmina von Chézy gerichteten Briefe mit farblicher Kennzeichnung des Geschlechts der Briefpartner. Graue Punkte markieren Personen ohne Normdaten, für die bislang keine Geschlechtsinformation vorliegt. [Screenshot der Visualisierung in correspSearch]
Aktiv gegen den Gender-Data-Gap
Wie in vielen anderen digitalen Diensten und Sammlungen besteht auch in correspSearch ein deutlicher Gender-Data-Gap. Dieser geht zum Teil auf historisch bedingte Ungleichheiten zurück, wird jedoch durch Überlieferungsbrüche und -lücken sowie eine häufig unzureichende Erschließung vorhandener Bestände weiter verstärkt.
Die systematische Aufarbeitung von Nachlässen wie dem Helmina von Chézys trägt dazu bei, Frauen als historische Akteurinnen im digitalen Raum sichtbarer zu machen und eröffnet neue, auch geschlechtergeschichtliche Perspektiven für die Forschung. Dieses Anliegen wird an der BBAW seit April 2026 von einer auf zwei Jahre geförderten Initiative „Gender & Data“ weitergeführt, die sich unter anderem mit der Rolle der Digital Humanities für eine inklusivere geisteswissenschaftliche Forschung befasst.
***
Mitwirkende an der Erschließung des Chézy-Nachlasses: Michael Rölcke (Bearbeiter), Bénédicte Savoy und Frederike Neuber (Leitung, Herausgeberschaft), Stefan Dumont und Steven Sobkowski (correspSearch), Sandra Miehlbradt (BBAW-Archiv).
