Humanities researchers today work across a fragmented landscape of digital tools. Citation managers know nothing about manuscript images. Transcription software has no connection to the writing environment. Collection metadata lives in spreadsheets that no other application can read. The result is not merely inconvenience; it is a structural barrier to the kind of cross-referencing, discovery, and synthesis that scholarship demands.
The prototype (early stage) Playfair Suite takes a different approach: a family of desktop applications for collection and source management (Playfair), academic writing (Scribe), manuscript analysis (Quire), OCR and transcription (Almanak), and prosopographical work (Proso), all built on a shared data layer. At the centre sits Playfair, which manages sources, entities, and metadata across the entire research lifecycle, and makes them available to every other application through embeddable views and a common interface. A citation entered in Playfair is immediately accessible while writing in Scribe. A manuscript catalogued in Playfair carries its metadata into analysis in Quire.
This talk introduces the architecture and vision of the Playfair Suite, demonstrates the integration between Playfair and Scribe, and asks what a truly integrated research environment could mean for humanities scholarship.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.academiccloud.de/gl/rooms/lou-eyn-nm6-t6b/join erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Der Webservice correspSearch, der historische Briefe durchsuchbar macht und vernetzt, hat einen wichtigen Meilenstein erreicht. Mit der jüngsten Integration der Briefe an Helmina von Chézy, die durch ein Explorationsprojekt an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) ermöglicht wurde, weist die Plattform nun mehr als 400.000 Metadatensätze von edierten oder wissenschaftlich erschlossenen Briefen nach.
Initiiert von der BBAW-Arbeitsgruppe „Gender & Data“ und mit institutioneller Unterstützung der Akademie wird seit 2025 an der Erschließung der Korrespondenzen in Helmina von Chézys Nachlass im Akademiearchiv gearbeitet (Mitwirkende s. u.). Innerhalb von acht Monaten wurde die umfangreiche Korrespondenz von rund 3.500 Briefen mit Unterstützung von TELOTA und unter Nutzung des CMIF Creators erfasst und für die Aufnahme in correspSearch vorbereitet. Etwa 2.000 Briefe wurden an Chézy gerichtet und knapp 1.400 von ihr verfasst. Erstere sind nun freigeschaltet, die Briefe von Chézy selbst werden in Kürze ebenfalls integriert. Zukünftig sollen die Informationen auch zurück in das Findbuch des BBAW-Archivs fließen, um die Nutzung der Bestände vor Ort zu verbessern.
Helmina von Chézy (1783–1856) war als Schriftstellerin, Journalistin und Intellektuelle in vielfältige Netzwerke eingebunden. Mit rund 20 Jahren ging sie nach Paris und verbrachte dort ein prägendes Jahrzehnt, in dem sie Kontakte zu den Romantikern Dorothea und Friedrich Schlegel knüpfte und journalistisch für französische und deutsche Zeitschriften arbeitete. Ein besonderes Kapitel stellte ihr humanitäres Engagement 1815/16 dar, als sie in Lazaretten in Köln und Namur verwundete Soldaten pflegte. Ihr kritischer Bericht über deren schlechte Behandlung führte zu einer Gefängnisstrafe, vor der sie nach Berlin floh, wo E. T. A. Hoffmann erfolgreich ihre Verteidigung übernahm. Ihre Dresdner Jahre (1817–1823) markierten einen Höhepunkt ihres Schaffens durch die Mitgliedschaft im Dresdner Liederkreis und die Zusammenarbeit mit Carl Maria von Weber am Libretto zur Oper „Euryanthe“.
Helmina von Chézys Korrespondenz bildet den zentralen Bestandteil ihres Nachlasses. Rund 3.500 Briefe dokumentieren ein weitreichendes Netzwerk aus Personen aus Literatur, Kunst, Politik und Verlagswesen. Die Briefe geben Einblick in literarische Arbeitszusammenhänge und soziale Beziehungen und zeigen zugleich die Lebensbedingungen einer Frau, die sich im frühen 19. Jahrhundert in einem überwiegend männlich geprägten kulturellen Umfeld behauptete. Ein nicht unerheblicher Teil der Korrespondenz entfällt auf den Austausch mit Frauen und verweist auf die Bedeutung weiblicher Netzwerke in dieser Zeit.
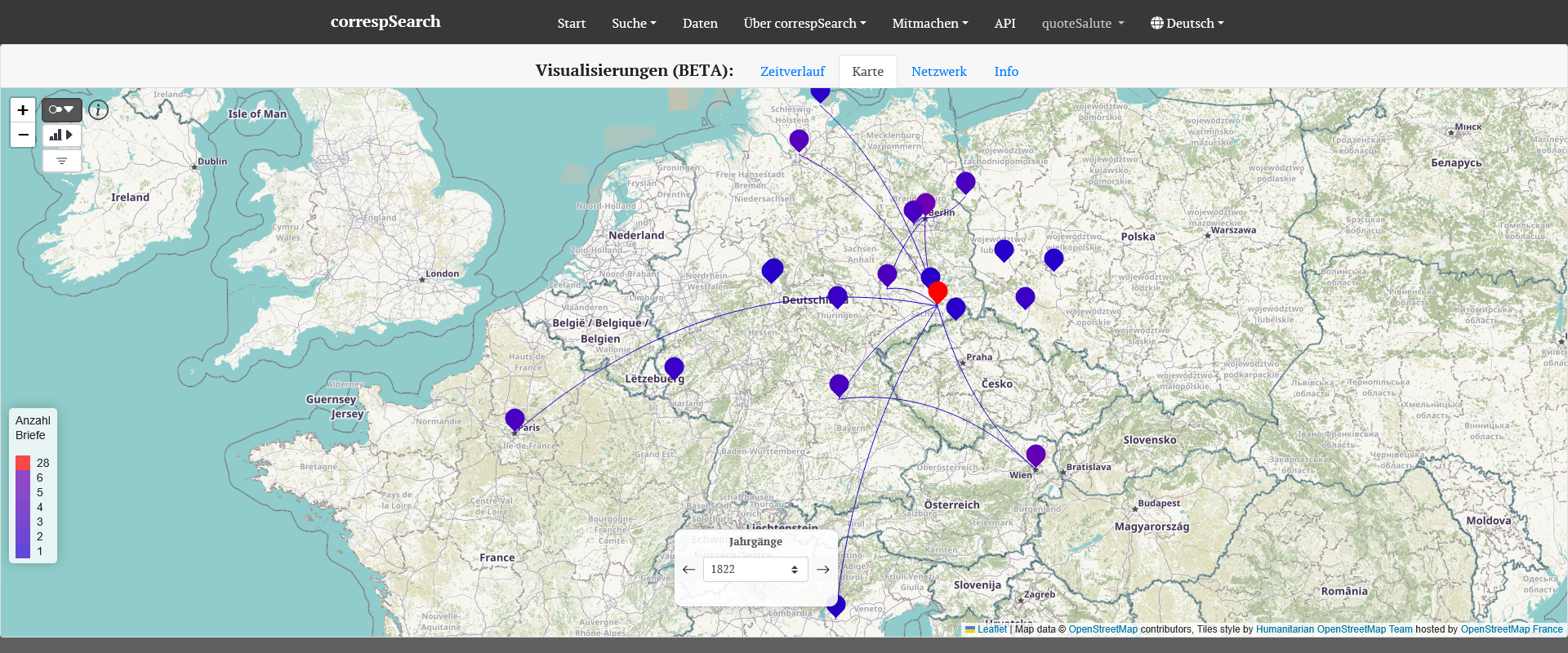
Helmina von Chézys internationales Briefnetzwerk im Jahr 1822 während ihres Aufenthalts in Dresden. [Screenshot der Visualisierung in correspSearch]
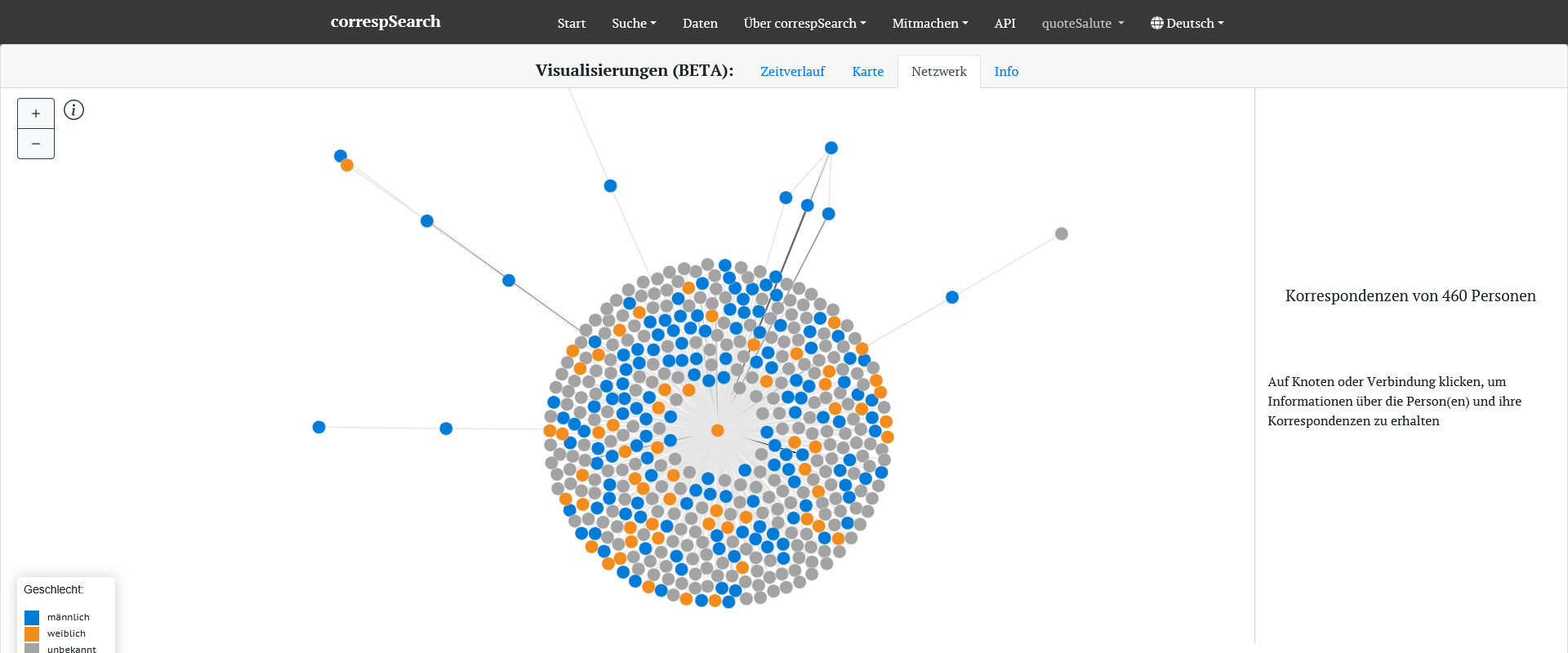
Netzwerk der an Helmina von Chézy gerichteten Briefe mit farblicher Kennzeichnung des Geschlechts der Briefpartner. Graue Punkte markieren Personen ohne Normdaten, für die bislang keine Geschlechtsinformation vorliegt. [Screenshot der Visualisierung in correspSearch]
Aktiv gegen den Gender-Data-Gap
Wie in vielen anderen digitalen Diensten und Sammlungen besteht auch in correspSearch ein deutlicher Gender-Data-Gap. Dieser geht zum Teil auf historisch bedingte Ungleichheiten zurück, wird jedoch durch Überlieferungsbrüche und -lücken sowie eine häufig unzureichende Erschließung vorhandener Bestände weiter verstärkt.
Die systematische Aufarbeitung von Nachlässen wie dem Helmina von Chézys trägt dazu bei, Frauen als historische Akteurinnen im digitalen Raum sichtbarer zu machen und eröffnet neue, auch geschlechtergeschichtliche Perspektiven für die Forschung. Dieses Anliegen wird an der BBAW seit April 2026 von einer auf zwei Jahre geförderten Initiative „Gender & Data“ weitergeführt, die sich unter anderem mit der Rolle der Digital Humanities für eine inklusivere geisteswissenschaftliche Forschung befasst.
***
Mitwirkende an der Erschließung des Chézy-Nachlasses: Michael Rölcke (Bearbeiter), Bénédicte Savoy und Frederike Neuber (Leitung, Herausgeberschaft), Stefan Dumont und Steven Sobkowski (correspSearch), Sandra Miehlbradt (BBAW-Archiv).
Janine Rauchmann (TU Darmstadt), Dr. Kerstin Roth (Universität Hamburg), Lisa Scharrer (TU Darmstadt), Dr. Josephine Ulbricht (BBAW)
Das Akademienvorhaben „Historische Fremdsprachenlehrwerke digital“ (FSL digital) widmet sich erstmalig der Volltexterschließung, korpuslinguistischen Aufbereitung, Annotation, digitalen Vernetzung sowie der sprach-, kultur- und wissenshistorischen Auswertung von mehrsprachigen Fremdsprachenlehrwerken aus der Frühen Neuzeit (15. – 17. Jahrhundert). Fremdsprachenlehrwerke der Frühen Neuzeit, die bis zu zehn Vernakularsprachen parallel abbilden, stellen eine genuin mehrsprachige Textsorte mit komplexem Layout dar. Somit bringen diese Quellen besondere Herausforderungen bei ihrer digitalen Aufbereitung mit sich. Um der inhaltlichen und strukturellen Heterogenität der Lehrwerke gerecht zu werden, bedarf es eines geeigneten Ansatzes zur (automatisierten) Texterkennung, der auch zukünftige Aspekte der Text- und Layoutannotation frühzeitig mitdenkt. In diesem Zusammenhang möchten wir die Quellengruppe und den aktuellen Workflow im Projekt vorstellen, welcher angesichts der großen Datenmenge einen Work-in-Progress darstellt und neben Text- und Layouterkennung auch das Postprocessing des OCR-Outputs sowie erste Ansätze zur Textannotation umfasst.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.academiccloud.de/gl/rooms/lou-eyn-nm6-t6b/join erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Ein partizipativer Workshop der Initiative „Datenzentrum – wissenschaftliche Konzeption und Ausgestaltung“ der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW)
Berlin, 25. und 26. Juni 2026; Akademiegebäude am Gendarmenmarkt; Einstein-Saal
Der Wert geisteswissenschaftlicher Forschungsdaten für Wissenschaft und Gesellschaft ist nicht zuletzt durch den laufenden Aufbau der Nationalen Forschungsdateninfrastruktur (NFDI) offensichtlich geworden. Zentrale Fragen nach dem dauerhaften Betrieb vertrauenswürdiger Datenrepositorien und der langfristigen Verfügbarkeit der aggregierten Inhalte sind jedoch weiterhin offen.
Vor diesem Hintergrund lädt die Initiative „Datenzentrum – wissenschaftliche Konzeption und Ausgestaltung“ der BBAW zu einem zweitägigen Lunch-to-Lunch-Workshop ein. Diese 2025 eingerichtete Initiative erarbeitet ein Konzept für die organisatorischen und technischen Grundlagen für ein leistungsfähiges, zertifiziertes Repositorium und dessen infrastrukturelle Einbindung innerhalb der BBAW. Darauf aufbauend wird die Akademie ab 2028 ein eigenes Datenzentrum betreiben. Dessen Hauptaufgaben werden die Aggregation, Verfügbarhaltung und Archivierung von Forschungsdaten, Software und Diensten aus den Vorhaben und Projekten der Akademie sein. Darüber hinaus ist eine Öffnung des Repositoriums für externe Datengeber:innen vorgesehen.
Im Workshop werden anhand von Impulsvorträgen die unterschiedlichen Perspektiven aus Sicht von Forschung, Bibliothek, Archiv und IT reflektiert. Anschließend bieten verschiedene Thementische die Möglichkeit zu einer intensiven Auseinandersetzung mit spezifischen Fragen, von der technischen Einrichtung nachhaltiger Infrastrukturen zwischen quelloffenen und kommerziellen Lösungen bis hin zum Einsatz sog. Künstlicher Intelligenz samt deren ethischen Herausforderungen.
Die Berlin-Brandenburgische Akademie der Wissenschaften sucht zwei wissenschaftliche Mitarbeiter:innen im Bereich Digital Humanities und Forschungssoftwareentwicklung für digitale Editionen (Standort Berlin).
Vollzeit (teilbar), befristet auf 24 Monate
Vergütung: E13 TV-L
Bewerbungsfrist: 07.04.2026
Aufgaben & Profil: Gesucht werden Bewerber:innen mit u.a. abgeschlossenem Hochschulstudium und Erfahrung in Digital Humanities, insbesondere in der Entwicklung von Forschungssoftware und APIs. Erwartet werden außerdem technisches Interesse (z. B. Machine Learning), Teamfähigkeit sowie gute Kommunikations- und Organisationsskills.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 16. Februar 2026, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Joshua Ramon Enslin (Freies Deutsches Hochstift | museum-digital)
Spätestens mit dem Aufkommen und der Popularisierung von KI-Chatbots wie ChatGPT hat die Diskussion um die Möglichkeiten des Einsatzes von Künstlicher Intelligenz auch die Museumsdokumentation erreicht.
In diesem Vortrag wird auf Basis eines generalisierten Lifecycles von Erschließungsdaten zu Museumsobjekten erst ein kurzer Überblick über bisherige Einsatzszenarien von KI mit dem Versuch einer Klassifikation präsentiert. Im Folgenden werden zwei im Rahmen der Initiative museum-digital entwickelte Einsatzszenarien im Detail beleuchtet.
museum-digital (https://www.museum-digital.org/) wurde 2009 in Bitterfeld von Museen gegründet, um gemeinsam die Bestände der Museen im Netz zu präsentieren. Ausgehend von der Publikation erweiterten sich die Aktivitäten und Softwarelösungen bald in andere, verwandte digitale Arbeitsfelder von Museen, besonders das Sammlungsmanagement und die Erstellung digitaler Ausstellungen. Heute arbeiten ca. 1700 Museen primär aus Deutschland, Ungarn und der Ukraine mit museum-digital, von denen bisher 1231 Objekte über die Plattformen veröffentlicht haben.
Die beiden Werkzeuge im Fokus des Vortrages sind Versuche, die Erschließungsarbeit der Museen weiter zu vereinfachen. Einerseits werden hierzu etwa bei Gemälden, Graphiken und Fotographien abgebildete Elemente automatisch erkannt und zur Verschlagwortung auf Basis des entsprechenden kontrollierten Vokabulars von museum-digital vorgeschlagen. Zentrale Fragen waren bei der Implementation einerseits die Anbindung bisher nicht auf die Arbeit mit Normdaten und kontrollierten Vokabularen ausgericheter Modelle an ein kontrolliertes Vokabular und die Frage, wie eine Klassifikation im Rahmen einer finanziell und in Bezug auf die zur Verfügung stehenden (Server-)Hardware stark eingeschränkten Community-Initiative umgesetzt werden können.
Das zweite hervorgehobene Werkzeug synthetisiert auf Basis bestehender, strukturierter Objektmetadaten Prosa-Objektbeschreibungen, die sowohl im Sinne der Barrierefreiheit als auch für die Auffindbarkeit der Objekte (besonders durch Suchmaschinen) bei museum-digital für die Publikation von Objekten verpflichtend vorausgesetzt werden. Hierzu werden die strukturierten Objektdaten auf Anfrage der Nutzenden in eine Prompt-Vorlage eingefügt. Auf Basis der Objektart werden ausgewählte, vorher als gut bewertete Beispielobjektbeschreibungen möglichst ähnlicher Objekte mitgegeben (Few-Shotting). Um Nutzende zu einer tatsächlichen kritischen Auseinandersetzung der generierten Texte zu bewegen, werden je drei, von verschiedenen Large Language Models generierte, Vorschläge generiert und angezeigt. Ist einer ausgewählt, werden Nutzende aufgefordert, den Text zu redigieren. Das Tool entstand experimentell im Rahmen einer Kooperation des Freien Hochstifts, des Zuse-Instituts Berlin, digiS‘ und von museum-digital. In diesem Kontext wurde für das Werkzeug ein engmaschiges Logging der generierten Daten und der Nutzerinteraktion implementiert, das tiefere Auswertungen zulässt – etwa, inwiefern die Texte tatsächlich redigiert wurden, und ob bestimmte Modelle, Textlängen, etc. von den Nutzenden präferiert wurden.
Der Vortrag schließt mit einem Ausblick auf die weiteren Potentiale und die durch die durch dank KI veränderte Umgebung aufgekommenen neuen Herausforderungen in der (digitalen) Erschließung und Publikation von Museumsbeständen.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 26. Januar 2026, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Bastian Politycki & Alexander Häberlin (Sammlung Schweizer Rechtsquellen (SSRQ))
Die Entwicklung nachhaltiger Forschungssoftware in den Digital Humanities ist kein rein mechanisches Unterfangen, sondern ein ständiger Aushandlungsprozess zwischen technischen Anforderungen, wissenschaftlicher Arbeit und Pflege der Codebasis. Am Beispiel der „Sammlung Schweizerischer Rechtsquellen“ (SSRQ) beleuchtet dieser Vortrag die Herausforderungen, eine komplexe, historisch gewachsene Editionsinfrastruktur technisch zukunftsfähig zu halten.
Im Zentrum steht die Adaption des professionellen Research Software Engineering (RSE) für den geisteswissenschaftlichen Alltag. Methoden wie Test-Driven Development (TDD) werden nicht nur zur Validierung von Code, sondern auch zur Qualitätssicherung historischer Daten eingesetzt, womit das notwendige „Vertrauen“ in die gedruckte und digitale Edition geschaffen wird. Gleichzeitig erfordert die langfristige Wartbarkeit ein kontinuierliches Refactoring der Codebasis.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 24. November 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Wolfgang Meier(Jinntec GmbH)
Der Vortrag stellt die neueste Version von TEI Publisher vor und demonstriert einige der wesentlichen Neuerungen. TEI Publisher 10 führt die Grundidee eines modularen Werkzeugkastens fort und implementiert sie auf einer höheren Ebene: an die Stelle einer zentralen Anwendung, die jeweils auf konkrete Editionsprojekte angepasst wird, tritt nun eine Sammlung von Profilen. Jedes Profil behandelt einen spezifischen Aspekt. Profile implementieren sowohl technische Grundlagen, wie z.B. die Unterstützung für ein bestimmtes XML-Format, Kommunikationsprotokoll oder Teile der Benutzeroberfläche, wie auch funktionale Aspekte, die auf einen bestimmten Editionstyp zugeschnitten sind, z.B. die Navigation zwischen Briefen einer Korrespondenz. Auch Webdesign und Darstellung werden durch Profile festgelegt und sind entsprechend austauschbar.
Eine digitale Editionsanwendung entsteht dann durch die Kombination unterschiedlicher Profile und deren Konfiguration. Letzere erfolgt über eine zentrale Konfigurationsdatei, zu der jedes Profil seine Parameter beiträgt und aus der die Anwendung erzeugt wird. Dies vereinfacht den Entwicklungsprozeß weiter, insbesondere für Anwender ohne Programmiererfahrung. Die Entwicklung kann darüber hinaus nun völlig iterativ erfolgen, d.h. es können jederzeit einzelne Profile hinzugefügt, verändert oder entfernt werden.
Die Aufteilung in Profile verbessert neben der Wiederverwendbarkeit insbesondere auch die Wartbarkeit der Anwendung: Updates können großteils automatisch durchgeführt werden, wenn sich einzelne Profile verändern. Bislang musste dagegen jeweils die gesamte Editionsanwendung manuell angepasst werden, um von einer neueren TEI Publisher-Version zu profitieren. Mit TEI Publisher 10 kümmert sich der zentrale Anwendungsmanager, Jinks, um die Aktualisierung aller Profile und ihrer Abhängigkeiten.
Nutzer können auch eigene Profile erstellen und in die Bibliothek von TEI Publisher integrieren. Dies macht zum einen dann Sinn, wenn bestimmte funktionale oder visuelle Aspekte automatisch auf mehrere Editionsprojekte angewandt werden sollen. So kann z.B. sichergestellt werden, dass alle Publikationen einer Institution eine einheitliche Gestaltung aufweisen und festgelegte Mindeststandards einhalten. Zum anderen können Projekte, die eine bestimmte Funktionalität benötigen, diese als generalisiertes Profil zu TEI Publisher beitragen und mit anderen Projekten teilen. Damit steigt die Wahrscheinlichkeit, dass das entsprechende Profil auch auf längere Sicht verfügbar bleibt und gewartet wird.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Marcus Lampert aus der TELOTA-Abteilung der BBAW stellt ein neues ediarum-Modul vor: ediarum.WEBDAV. Vor einem Jahr an der BBAW eingeführt, verfolgt ediarum.WEBDAV das Ziel, ein sicheres und transparentes System für das Bearbeiten, Speichern und Sichern von XML-Forschungsdaten bereitzustellen. Mittlerweile nutzen bereits fast zehn Projekte an der BBAW die Software täglich.
Marcus wird die Software aus verschiedenen Blickwinkeln vorstellen: Zunächst demonstriert er, wie Nutzerinnen und Nutzer über Oxygen und die Benutzeroberfläche mit dem System arbeiten. Anschließend zeigt er, wie ediarum.WEBDAV automatische Git-Commits verwendet, um XML-Forschungsdaten zuverlässig zu speichern und zu sichern. Schließlich werden wir gemeinsam einen Blick auf Teile des Codes werfen, um zu verstehen, wie das Laravel-Framework die verschiedenen Komponenten der Software koordiniert.
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/nad-mge-0rq-ufp erreichbar.
Das ediarum.MEETUP ist primär für DH-Entwickler:innen gedacht, die sich zu spezifischen ediarum-Entwicklungsfragen austauschen wollen, jedoch sind auch ediarum-Nutzer:innen und Interessierte herzlich willkommen.
Wir freuen uns auf zahlreiches Erscheinen!
Viele Grüße Nadine Arndt im Namen der ediarum-Koordination
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 27. Oktober 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Tim Westphal (BBAW, TELOTA), Marco Santi (BBAW), Mario Tormo Romero(Hasso-Plattner-Institut, Potsdam)
Seit Beginn der Arbeit an einer historisch-kritischen Edition Gottfried Wilhelm Leibniz im Jahr 1901 bildet die Datierung des umfangreichen handschriftlichen Nachlasses eine große editorische Hürde. Rund 100.000 Blätter aus der Hand des letzten Universalgelehrten dokumentieren eine über fünf Jahrzehnte reichende intellektuelle Entwicklung, wobei einem Großteil der Schriftstücke eine zeitgenössische Datierung fehlt. Traditionelle Methoden der Datierung sind für einen Korpus dieser Dimension unzureichend: Die manuelle Bestimmung durch Expertinnen ist angesichts der Materialmenge praktisch nicht zu bewältigen, und auch die Wasserzeichenanalyse erlaubt nur grobe Annäherungen im Bereich von Jahrzehnten.
Der Beitrag erprobt, inwieweit bildgestützte Deep-Learning-Modelle diese Lücke schließen können und ob diese dabei eine editorisch nutzbare Genauigkeit erreichen. Wünschenswert ist eine maximale Abweichung von ±1 Jahr. Im Mittelpunkt steht die Frage, ob Deep-Learning-Modelle die feinen intra-personalen Schreibdrifts eines einzelnen Autors über fast fünf Jahrzehnte abbilden können. Anders als bestehende Arbeiten, die meist das Alter verschiedener Schreiber klassifizieren, zielt der Ansatz auf die Detektion des schreibereigenen Stilwandels innerhalb Leibniz‘ Werk. Der weitläufige Nachlass von Leibniz bietet hierfür eine geeignete Grundlage.
Es wird bewusst auf Transkription oder OCR verzichtet, so werden die besonderen Herausforderungen von Leibniz‘ Schriftbild (Überarbeitungen, Streichungen, wechselnde Sprachen) umgangen. Um sicherzustellen, dass die Modelle schriftbezogene und nicht materialbedingte Merkmale lernen, werden verschiedene Normalisierungsschritte durchgeführt: Zeilenweise Segmentierung und Binarisierung eliminieren Papierstruktur und Tintenintensität als Faktoren.
Als Datenbasis dienen ca. 600 Seiten aus dem Zeitraum 1669-1716: 400 datierte Briefe sowie 200 Seiten wissenschaftlicher Ausarbeitungen. Das Material wurde so gewählt, dass für jedes Jahr Vorlagen verfügbar sind. Es werden verschiedene Deep-Learning-Architekturen entwickelt und evaluiert, die relevante Merkmale direkt aus den Bilddaten lernen. Anders als klassische Ansätze der digitalen Paläographie mit manueller Merkmalsextraktion wird auf ein Ende-zu-Ende-Lernverfahren gesetzt. Ziel des Projekts ist die Entwicklung von Ansätzen zur hochauflösenden Datierung frühneuzeitlicher Gelehrtenhandschriften für den Einsatz in der alltäglichen editorischen Praxis. Die entwickelte modulare Pipeline ermöglicht flexibel konfigurierbare Experimente und legt besonderen Wert auf Visualisierung und Erklärbarkeit der Ergebnisse.
Das Projekt positioniert sich an der Schnittstelle von Digital Humanities und Computer Vision und zeigt, wie klassisches maschinelles Lernen die traditionelle editorische Arbeit ergänzen kann. Es entsteht in Kooperation zwischen der Leibniz-Arbeitsstelle der BBAW, dem DH-Referat TELOTA und dem KI-Servicezentrum des Hasso-Plattner-Instituts in Potsdam.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Bei TELOTA an der Berlin-Brandenburgischen Akademie der Wissenschaften ist derzeit eine Stelle im Bereich Digital Humanities und Forschungssoftwareentwicklung für Digitale Editionen im Umfang von 100 % der regelmäßigen wöchentlichen Arbeitszeit ausgeschrieben. Die Stelle ist vorerst befristet auf 24 Monate (ggf. teilbar). Bewerbungsfrist ist der 21.10.2025.
Entwurf, Entwicklung und Anpassung von zentralen, digitalen Forschungswerkzeugen und -umgebungen der BBAW
Entwurf und Entwicklung von Daten- und Programmierschnittstellen (APIs) zur Visualisierung und Vernetzung von Forschungsdaten
Weiterentwicklung digitaler Methoden unter Einsatz aktueller Technologien wie Machine Learning oder Knowledge Graphs
Dokumentation der Entwicklungsarbeiten
Mitarbeit bei der Antragstellung und Berichterstattung von Projektanträgen im Rahmen von regionalen, nationalen und internationalen Forschungsförderungen
Präsentation der Arbeits- und Forschungsergebnisse auf einschlägigen Konferenzen und Workshops
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 29. September 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Fernanda Alvares Freire (BBAW, TELOTA)
This presentation explores how Social Network Analysis (SNA) can be applied to study social interactions as represented in historical letter corpora. By combining qualitative text analysis with Social Network Analysis (SNA), the approach models and visualizes interpersonal relations to investigate patterns of interaction, the roles of key actors, and the structure of historical communities. As one of the largest collections from the Hellenistic period, the letters and documents of the Zenon archive provide rich information about administrative, economic, and personal networks and serve as an exemplary use case to the approach. Applying SNA to this corpus highlights the potential and challenges of working with large corpora of written communication and serves as an example of how this framework can be extended to other epistolary datasets.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 14. Juli 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Fabian Moss (Julius-Maximilians-Universität Würzburg) über Text+ Musik: Multimodale Kodierungsherausforderungen im DigiMusTh-Kooperationsprojekt
***
Das Text+-Kooperationsproject »DigiMusTh« hat den Aufbau einer offenen digitalen Sammlung historischer musiktheoretischer Texte aus dem deutschsprachigen Raum anhand von Beispielen aus dem 19. Jahrhundert zum Ziel. Diesem Unterfangen stehen eine Reihe besonderer Herausforderungen gegenüber, die sich vornehmlich aus der Multimodalität der Dokumente ergeben, welche neben Text auch Bilder, Grafiken, sowie Musiknotation enthalten. Der Beitrag präsentiert den aktuellen Stand des Projekts, erläutert einige dieser Herausforderungen und stellt Lösungsvorschläge zur Debatte.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Zum Thema Encoding Gender kündigen wir folgende Beiträge an:
Themenblock Kodierung
Nadine Arndt (BBAW/TELOTA): Auszeichnung von „sex“ & „gender“ in ediarum
Marius Hug und Frank Wiegand (BBAW/Text+): Bevorzugte Waffen der Frauen – Annotationen im Deutschen Textarchiv als Voraussetzung für eine genderspezifische Korpusanalyse mit dem DWDS
Themenblock Normdaten
Sabine von Mering (Museum für Naturkunde Berlin): Das Potenzial von Wikidata für die Sichtbarmachung von Frauen – Gender data gap in der Naturkunde
Julian Jarosch, Denise Jurst-Görlach und Thomas Kollatz (Akademie der Wissenschaften und der Literatur Mainz): Genderattribution in der GND und entityXML am Beispiel der Korrespondenz Martin Bubers
Das Meetup soll den Austausch fördern, Problemfelder identifizieren und gemeinsam Lösungsansätze erarbeiten. Wir freuen uns auf vielseitige Perspektiven und eine lebhafte Diskussion!
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/nad-mge-0rq-ufp erreichbar.
Das ediarum.MEETUP ist primär für DH-Entwickler:innen gedacht, die sich zu spezifischen ediarum-Entwicklungsfragen austauschen wollen, jedoch sind auch ediarum-Nutzer:innen und Interessierte herzlich willkommen.
Wir freuen uns auf zahlreiches Erscheinen!
Viele Grüße Nadine Arndt und Frederike Neuber im Namen der ediarum-Koordination und der Gender & Data-Arbeitsgruppe
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 26. Mai 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Philipp Bayerschmidt und Cord Pagenstecher über Oral-History.Digital – Der Aufbau eines Interviewportals und die Erschließung heterogener Archive mit Topic Modeling
***
Das Interviewportal „Oral-History.Digital“ ist eine von der Freien Universität Berlin betriebene Erschließungs- und Recherche-Plattform für wissenschaftliche Sammlungen von audiovisuellen Forschungsdaten (www.oral-history.digital). Universitäten, Museen und Stiftungen können ihre Audio- und Video-Interviews hochladen, mit Werkzeugen für Transkription oder Verschlagwortung bearbeiten und mit einem granularen Rechtemanagement für Bildung und Wissenschaft bereitstellen. Interessierte können die inzwischen über 4000 Interviews von rund 40 Institutionen sammlungsübergreifend durchsuchen. Angemeldete Nutzende können die Aufnahmen mit Untertiteln ansehen, annotieren und zitieren.
Zur Unterstützung der teilnehmenden Interviewarchive hat die an „Oral-History.Digital“ mitwirkende FernUniversität Hagen einen Topic-Modeling-Service entwickelt, der die automatische Erstellung von Inhaltsverzeichnissen und Themenregistern unterstützt. Grundlage ist ein auf Basis von 991 Interviews aus sieben verschiedenen Archiven berechnetes und evaluiertes Topic-Modell. Über ein Register von 100 Topics können nun gezielt Textpassagen zu entsprechend gelabelten Themen gefunden werden. Der Orientierung innerhalb der mehrstündigen Interviews dienen klickbare Inhaltsverzeichnisse, die aus den Topics erzeugt wurden. Zudem unterstützt ein interaktives Dashboard die Analyse der Interviews.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Im Namen des Konsortiums Text+ der Nationalen Forschungsdateninfrastruktur (NFDI) und des ediarum-Teams an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) sowie in Kooperation mit der Gender & Data-Arbeitsgruppe der BBAW freuen wir uns, das nächste virtuelle ediarum.Meetup anzukündigen:
Neben einer Einführung in die Thematik und einer Vorstellung der ediarum-Funktion zur Kodierung von Sex und Gender laden wir Projekte, die sich mit der Kodierung von Gender beschäftigen, ein, kurze Beiträge (ca. 5–10 Minuten) einzureichen. Das Meetup soll den Austausch zu diesem Thema fördern, Problemfelder identifizieren und gemeinsam Lösungsansätze erarbeiten. Ob Herausforderungen bei der Modellierung oder konkrete Lösungsansätze in TEI/XML – wir freuen uns auf vielseitige Perspektiven und eine lebhafte Diskussion!
Wenn Sie einen 5- bis 10-minütigen Impulsbeitrag zum Thema „Encoding Gender“ leisten möchten, senden Sie bitte eine kurze, informelle Beschreibung Ihres Beitrags bis zum 15. Mai 2025 an neuber@bbaw.de.
Viele Grüße,
Nadine Arndt und Frederike Neuber im Namen der ediarum-Koordination und der Gender & Data-Arbeitsgruppe
* Aus organisatorischen Gründen weichen wir diesmal leicht vom angestammten Rhythmus ab.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 24. Februar 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Hannes Bajohr (University of California, Berkeley) über Distanzierte Autorschaft
***
Der Vortrag gibt einen Überblick über den Begriff der Autorschaft in KI und in Systemen zur Verarbeitung natürlicher Sprache und erörtert frühere und aktuelle Debatten über Computer als literarische Autoren. Er schlägt das Konzept der kausalen Autorenschaft vor, um die Arten der Distanz zwischen menschlichen und maschinellen Agenten zu messen, wobei er die anthropozentrische Ausrichtung dieser Idee anerkennt. Als Gegengewicht dazu wird der Begriff der verteilten Autorschaft diskutiert, der das Netzwerk der an der Entstehung eines Textes beteiligten Akteure berücksichtigt und seine eigenen Grenzen hat. Beide Konzepte sind Elemente einer zukünftigen Theorie der Autorschaft im Zeitalter des maschinellen Lernens.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich ein zum ersten Termin im neuen Jahr am Montag, den 27. Januar 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Simone Franz über Wissen im Netzwerk. Praxisrelevante Ansätze zur Überführung von Forschungsdaten digitaler Editionen in Knowledge-Graphen
***
Der Vortrag beleuchtet das Zusammenspiel digitaler Editionen, Knowledge-Graphen und bibliothekarischer Wissensorganisation. Dabei nehmen Terminologien wie kontrollierte Vokabulare, Normdaten und Ontologien als vermittelnde Elemente für die disziplinübergreifende semantische Vernetzung von Forschungsdaten und die Wissenskodierung eine zentrale Rolle ein.
Ausgehend von einer Kombination semi-strukturierter Leitfadeninterviews sowie einer Datenmodellierung stellt der Vortrag ausgewählte empirische Befunde zur Analyse des Potentials von Knowledge-Graphen für digitale Editionen vor. Vor dem Hintergrund des Aufbaus von Knowledge-Graphen in den geistes- und kulturwissenschaftlichen Konsortien der Nationalen Forschungsdateninfrastruktur (NFDI) geht er der Frage nach, wie Forschungsdaten digitaler Editionen (bspw. XML/TEI-Registerdateien) semantisch angereichert, geöffnet und nachnutzbar gemacht werden können, um sie in Knowledge-Graphen zu überführen. Dabei werden unter anderem Gender Biases in Wissensbasen, Datenqualität und -herkunft sowie die Bedeutung wissenschaftlicher Bibliotheken und Informationsinfrastrukturen diskutiert.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Die Berlin-Brandenburgische Akademie der Wissenschaften sucht für die Mitarbeit im Akademienvorhaben KIŠIB sowie für ihr Referat TELOTA zur Mitarbeit in weiteren Vorhaben der bild- und objektbasierten Forschung zum frühestmöglichen Zeitpunkt eine/einen wissenschaftliche/n Mitarbeiter/in (m/w/d) im Bereich Informatik und Archäoinformatik / Digital Cultural Heritage / Digital Humanities im Umfang von 100% der vollen tariflichen Arbeitszeit, vorerst befristet auf 24 Monate, ggf. teilbar.
Das Referat TELOTA an der Berlin-Brandenburgische Akademie der Wissenschaften sucht eine*nwissenschaftliche*n Mitarbeiter*in im Bereich digitale Editionen, Schwerpunkt Briefeditionen und Entwicklung und Analyse mit X-Technologien und Python. Die Vollzeitstelle ist auf 24 Monate befristet und nach E13 TV-L Berlin vergütet.
Die BBAW bietet ein attraktives Arbeitsumfeld in Berlin-Mitte mit familienfreundlichen Arbeitsbedingungen. Zu den Zusatzleistungen gehören 30 Urlaubstage, betriebliche Altersvorsorge, vermögenswirksame Leistungen und ein VBB-Firmenticket-Zuschuss. Die Position ermöglicht die wissenschaftliche Weiterentwicklung in einem aktiven Digital-Humanities-Umfeld und die Mitarbeit in einem engagierten Team.