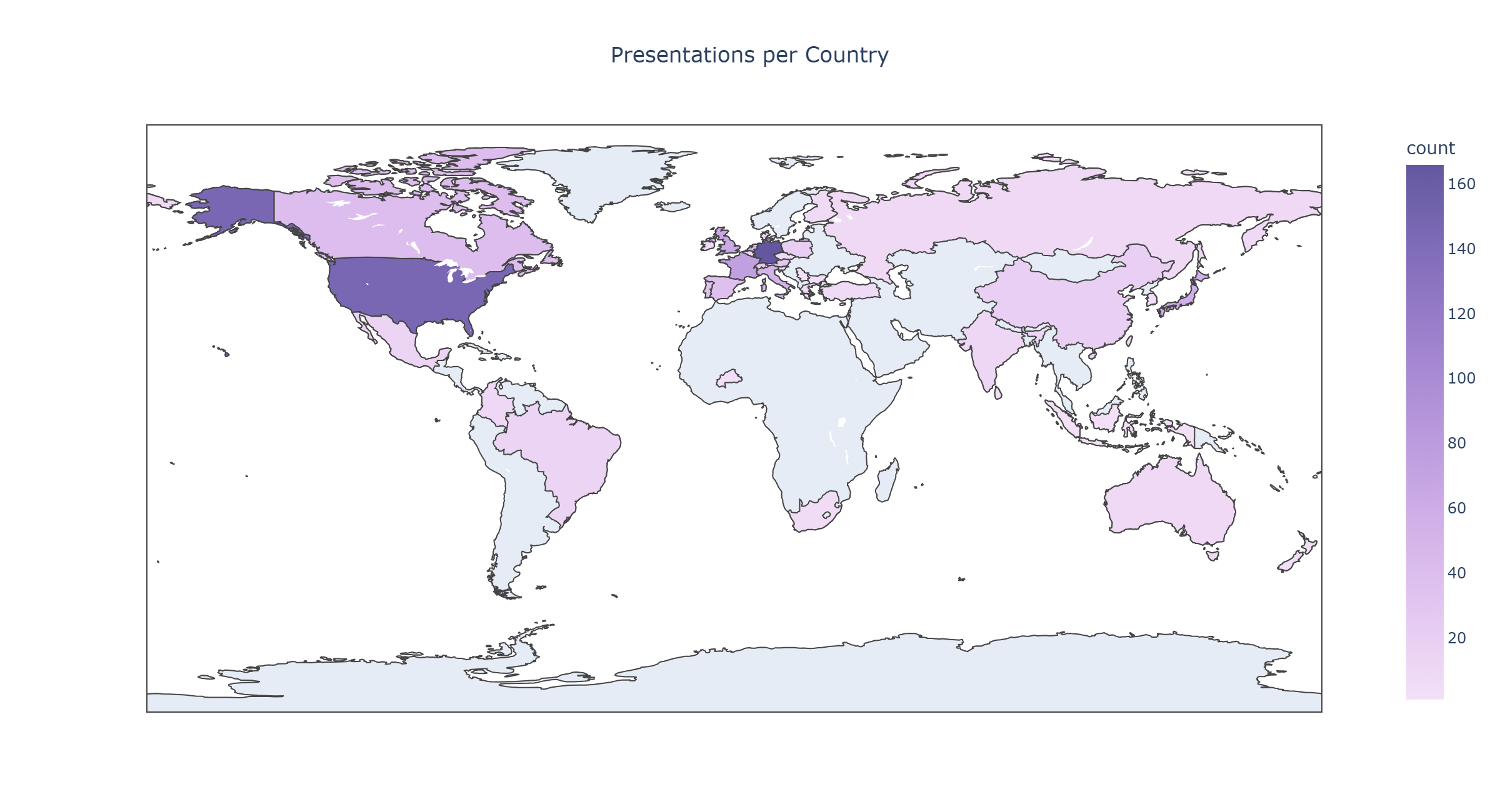
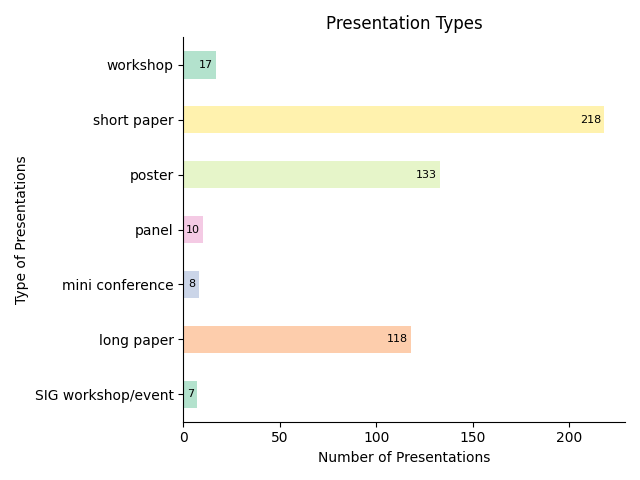
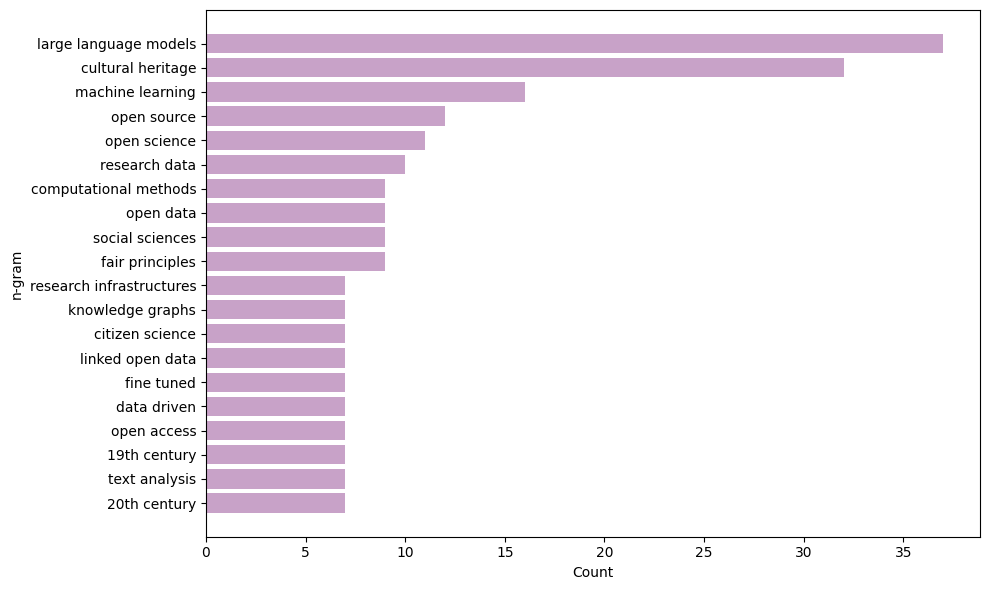
Dank der Unterstützung des Verbands der Digital Humanities im deutschsprachigen Raum in Form eines Reisestipendiums konnte ich an der DH Konferenz 2025 in Lissabon, Portugal, teilnehmen.
Passend zu diesem Beitrag entstand auch ein Vlog, der hier auf YouTube verfügbar ist.
Unter dem Motto „Building access and accessibility open science to all citizens” fand vom 14. bis 18. Juli 2025 in Lissabon die Konferenz für Digital Humanities 2025 statt. Als Masterstudentin im letzten Semester war es für mich eine großartige Gelegenheit, an der Konferenz teilzunehmen und vor allem ein Universitätsprojekt vorstellen zu können. Es war auch eine Gelegenheit, den Forschungsaspekt der Digital Humanities zu erkunden und viel über verschiedene Projekte, Techniken und Pläne in diesem Bereich zu lernen. Bei dieser ersten Erfahrung war ich glücklicherweise nicht alleine, sondern wurde von einem Kollegen begleitet, der ebenfalls an dem zu präsentierenden Projekt mitgearbeitet hatte, sowie von unseren Professoren, die unsere Arbeit betreut haben.
Teilnahme an den Vorträgen
Obwohl die Konferenz bereits am Montag, dem 14. begann, kam ich erst am Mittwochabend an und war nur an den letzten beiden Tagen, Donnerstag und Freitag, anwesend. Dies lag hauptsächlich an den verfügbaren Flügen, Unterkünften, Kosten und der Möglichkeit, mir frei zu nehmen. Das bedeutet jedoch nicht, dass ich Zeit verschwendet habe. Die Workshops waren zu diesem Zeitpunkt bereits vorbei, aber mein Terminkalender war mit der Teilnahme an vielen verschiedenen Vorträgen zu einem breiten Spektrum von Themen, Methoden und Möglichkeiten gefüllt. Im Folgenden werden einige dieser Vorträge hervorgehoben, die meinen verschiedenen Interessengebieten nahe standen und die ich nicht nur aus technischer Sicht, sondern auch aus persönlichem Interesse am interessantesten fand.
Die erste Sitzung umfasste drei Vorträge zu den Themen Machine Learning (ML), Netzwerkanalyse und Diskursanalyse. Der erste Vortrag, gehalten von Mark Andrew Algee-Hewitt und Jessica Monaco, konzentrierte sich auf die Anwendung von Machine Learning, insbesondere eines BERT-Modells, zur Klassifizierung einzelner Passagen aus gotischen Romanen des 19. Jahrhunderts anhand ihrer Verbindungen zu anderen modernen, nicht-gotischen Genres. Der Vortrag lieferte nicht nur wertvolle Einblicke in verschiedene Romane, sondern stellte auch einen innovativen Ansatz zur Verfolgung von Veränderungen der Genremerkmale im Laufe der Zeit vor. Für mich war dies ein sehr interessantes Projekt, da ich Literatur als Teil meiner täglichen Hobbys genieße und es interessant und unterhaltsam fand, sie im Kontext der Digital Humanities präsentiert und untersucht zu sehen, insbesondere in Kombination mit Machine Learning, einem weiteren Interesse von mir, das ich während meines Studiums entwickelt habe. Da ich bisher noch nicht mit BERT-Modellen gearbeitet habe, bot dieser Vortrag gute Einblicke in das Modell, seine Verwendung und sein Potenzial.
In derselben Sitzung stellte Zef Segal seine Arbeit über die Kulturen der Wiederverwendung von Texten vor und verglich dabei amerikanische und hebräische journalistische Netzwerke aus dem 19. Jahrhundert. Die Sitzung wurde von Caoi Mello abgeschlossen, der verschiedene Strategien zur Identifizierung von Nuancen in Zeitungen vorstellt, die bis heute mit computergestützten Methoden nur schwer zu erreichen sind.
Die zweite Sitzung des Tages hatte als Hauptthema die Netzwerkanalyse. Der erste Vortrag von Christophe Malaterre und Francis Lareau befasste sich mit einer Methode zur Ableitung semantischer sozialer Netzwerke aus Textdaten. Dabei werden die Ähnlichkeiten in der Terminologie mithilfe von Topic Modelling analysiert. Dieser Ansatz hilft dabei, „hidden communities of interest” zu identifizieren, um die Entwicklung von Gemeinschaften analysieren zu können.
In derselben Sitzung erfuhr ich auch von den anderen Vorträgen und deren Nutzung von Netzwerken zur Unterstützung ihrer Forschung. Evelien de Graaf nutzt beispielsweise Co-occurrences in altgriechischen und lateinischen Texten, um die Erwähnungen von Platon in der vorchristlichen Literatur zu kartieren. Anschließend stellten Caio Mello seinen und den Ansatz seiner Kollegen Jen Pohlmann und Karin León Henneberg vor, indem sie die Debatte über das NetzDG, das neue deutsche Gesetz gegen Hassreden, untersuchten. Sie verwendeten Netzwerkanalysen, Methoden der Natural Language Processing und Close Reading, um getwitterte Inhalte verschiedener Accounts zu untersuchen, die das Gesetz erwähnten, um den potenziell hohen Einfluss dieser Accounts auf die Gestaltung der Diskussion zu diesem Thema zu untersuchen.
Anschließend stellte Katherine Ireland ihre vorläufige R Shiny Web-App vor, mit der sich die Tweet-Datensätze des National Health Service (NHS), des Center for Disease Control (CDC) und der Weltgesundheitsorganisation (WHO) aus dem Jahr 2020 visualisieren lassen. Die Web-App sieht eine interaktive Visualisierung der Datensätze vor, bietet aber auch die Möglichkeit der Textanalyse mit Tidytext und Quanteda.
Schließlich stellten Paul Girard, Alexis Jacomy, Benoît Simard und Mathieu Jacomy ihre Lite Webversion von Gephi vor: Gephi Lite. Die Hauptfunktionen bieten eine demokratisierte Netzwerkvisualisierung, die über eine Webplattform verfügbar ist.
Präsentation unseres Projekts
In der folgenden Sitzung stellten wir unser Projekt vor. Dies war für uns, zwei Masterstudenten, die von unseren beiden Professoren betreut und unterstützt wurden, eine großartige Gelegenheit, die Forscherseite der Digital Humanities als aktive Teilnehmer zu erleben.
Das Projekt selbst bestand in der Rekonstruktion der Verwendungskontexte der Sortes-Texte, einer beliebten Art interaktiver und divinatorischer Texte, die erstmals in der Spätantike auftauchen und im Mittelalter in Europa weit verbreitet waren. Anhand der Prenostica Socratis Basilei, einer Handschrift von Konrad Bollstatter aus den Jahren 1450 bis 1473, die als Grundlage für die Edition diente, wollten wir das „Äußere” dieser Editionen untersuchen. Das bedeutete, dass wir uns eher auf die Verwendungskontexte als auf den Inhalt des Textes konzentrierten.
Die Besonderheit der Sortes-Texte besteht darin, dass sie nicht linear und in hohem Maße interaktiv sind und performative Handlungen wie Würfeln, Kartenlegen usw. verwenden. Wissenschaftler haben sich bisher auf den Textinhalt konzentriert, aber nur sehr wenig Interesse an der nicht-textuellen Dimension dieser Texte gezeigt. Unser Projekt zielt darauf ab, diese andere wichtige Dimension der Sortes-Texte zu erschließen.
Wir haben daher eine Virtual Reality Anwendung bzw. ein Spiel entwickelt, das den bekannten Verwendungskontext im Mittelalter als wissenschaftliches Werkzeug, als Spiel und als religiöses Objekt rekonstruiert. Mithilfe der Quixel Megascan Bibliothek von Unreal Engine haben wir versucht, die Atmosphäre nachzubilden, in der die Texte möglicherweise verwendet wurden, wobei wir die historische Genauigkeit etwas außer Acht gelassen haben. In dem Projekt ist es möglich, die Verwendung des Buches und die erforderlichen Würfeln zu erleben sowie die verschiedenen Atmosphären zu genießen und zu erleben, wobei einige selbst erstellte 3D-Modelle auf der Grundlage historischer, dokumentierter Objekte verwendet werden.
Diese Präsentation war meine allererste im Rahmen einer Digital Humanities Konferenz, und der Stress war ziemlich hoch. Als ich jedoch zu sprechen begann, verlief im letzten Teil der Präsentation alles reibungslos, obwohl mir einige Sprachfehler unterliefen, die sich jedoch als völlig unproblematisch herausstellten. Die Fragerunde nach unserer Präsentation war für mich wahrscheinlich die größte Herausforderung, da die anwesenden Personen Doktoranden oder renommierte Forscher auf dem Gebiet der Digital Humanities waren. Sie zeigten mir jedoch, dass das Projekt tatsächlich interessant war und einen Beitrag zu den Digital Humanities leisten konnte. Sie bewiesen uns, meinem studentischen Kollegen und mir, dass wir unsere Projekte nicht herabsetzen, sondern stolz darauf sein sollten. Wir konnten die gestellten Fragen beantworten, und es entstand eine gute Diskussion über unsere Präsentation.
Diese erste Präsentationserfahrung war positiv und hat mir die Augen für die Möglichkeit eröffnet, meine Karriere in der Forschung im Bereich der Digital Humanities fortzusetzen. Die Diskussionen, die wir geführt haben, und die Menschen, die wir getroffen haben, haben wirklich zu einer positiven Gesamterfahrung beigetragen, und ich habe durch das Feedback in der Diskussion nach unserem Präsentationsblock viel Selbstvertrauen in mich selbst und die Projekte gewonnen. Diese Präsentationserfahrung war etwas, das ich nicht erwartet hatte, und hat mir geholfen, mehr über eine weitere mögliche Zukunft nach meinem Masterstudium zu erfahren.
Die Diskussionen ermöglichten es uns auch, andere Richtungen für unser Projekt in Betracht zu ziehen, wie beispielsweise die Verwendung von Augmented Reality statt Virtual Reality, die Veröffentlichung des Spiels auf Steam für einen besseren Zugang oder sogar die Hinzufügung weiterer Anwendungskontexte für die Sortes oder die Erweiterung der möglichen Barrierefreiheit. Unsere Entscheidungen wurden ebenfalls respektvoll hinterfragt und diskutiert, was mir ermöglichte, die Entscheidungen hinter dem Projekt näher zu erläutern und mir bewusst zu machen, dass ich trotz meiner geringen Erfahrung der Community etwas Neues und Interessantes vorschlagen konnte.
Nach der Präsentation habe ich keine weitere Sitzung besucht, da wir in viele verschiedene Gespräche mit Leuten verwickelt waren, die unsere Präsentation gesehen hatten und außerhalb der vorgesehenen Zeit weiter über das Projekt, die Techniken und unsere Überlegungen dazu diskutieren wollten. Obwohl ich die letzte Präsentationssitzung des Tages verpasst habe, haben mir diese zusätzlichen Gespräche und das Interesse der anderen Teilnehmer wirklich die Augen für die vielen Möglichkeiten und das Interesse geöffnet, die in den Digital Humanities zu finden sind.
Der letzte Tag der Konferenz
Am letzten Tag der Konferenz nahm ich im Gegensatz zum Donnerstag an allen möglichen Sitzungen teil, darunter auch an einer Panel-Diskussion, die sich in ihrem Format leicht von den anderen Präsentationen unterschied.
Im ersten Block stellten Glenn Roe, Valentina Fedchenko und Dario Nicolosi ihre Methoden vor, bei denen sie mithilfe einer fine-tuned BERT- und CamemBERT-Modelle diachrone semantische Verschiebungen in historischen Teilkorpora identifizierten. Dabei zeigten sich nuancierte Veränderungen in Schlüsselkonzeptclustern, die zur Weiterentwicklung der Methoden in der computergestützten Geistesgeschichte beitrugen.
Anschließend stellten Han-Chun Ko, Pin-Yi Lee, Ya-Chi Chan und Richard Tzong-Han Tsai ihr Framework zur Erklärung historischer Daten mithilfe von Graphen und Large Language Models (LLMs) vor. Dieser Vortrag war für mich besonders interessant, da die Referenten sehr detailliert auf die technischen Aspekte und Methoden eingingen, mit denen sie die LLMs in ihr System integrieren, um ihre Daten zu interpretieren. Es war eine interessante technische Präsentation, bei der ich sehen konnte, was ich bereits wusste und was ich noch lernen konnte.
In der letzten Präsentation stellte Paul Barrett sein aktuelles Forschungsprojekt vor, dessen Ziel es war, mithilfe von Methoden wie Named-Entity Recognition (NER), des Machine Learning (ML) und Optical Character Recognition (OCR) die neu entdeckte indigene Zeitschrift von John Norton, Teyoninhokarawen, zu modellieren und zu analysieren.
In dem folgenden Präsentationsblock stellten verschiedene Entwickler und Forscher ihre Projekte vor, die darauf abzielen, die Arbeit mit rechnergestützten technischen Aspekten in den Digital Humanities zu erleichtern. Von CodeFlow, einem automatisierten Codegenerator, der über LLMs optimiert wurde, zu Pandore, einer automatischen Textverarbeitungs-Workflow-Toolbox, zu FlowFilter, einem Visualisierungs- und Filtertool für große und detaillierte Datensätze, bis hin zu den Diskussionen über OpenScience Literacy in den Digital Humanities, jeder Vortragende stellte nützliche und unglaubliche Tools vor, von denen ich noch nie gehört hatte, die sich aber als sehr interessant herausstellten. Das hat mir die Augen für die Verfügbarkeit und den Bedarf von Forschern in den Digital Humanities geöffnet.
Die nächsten Vorträge waren Teil des Panels „Rethinking the Ethics of „Open“ in the Shadow of AI”, das sich mit der Ethik und den Herausforderungen in der modernen Digital Humanities Forschung befasste, insbesondere angesichts der Tatsache, dass künstliche Intelligenz mittlerweile eine wichtige Rolle im Alltag spielt. Obwohl die Präsentation recht lang war und den Diskussionsprozess, wie er normalerweise in einem Panel stattfindet, behinderte, gelang es mir, Informationen zu diesem Thema aus verschiedenen Perspektiven zu sammeln: data sovereignty, Projektdesign und Datenschutz, Pädagogik und künstlerische Arbeit, alles Themen, die wir auch im Masterstudium kurz angeschnitten hatten und die zeigen, wie wichtig es ist, sich mit diesen Fragen auseinanderzusetzen.
Der letzte Präsentationsblock ermöglichte mir, verschiedene Themen kennenzulernen. Zunächst stellten Andreas Niekler, Vera Piontkowitz, Sarah Schmidt, Janos Borst-Graetz und Manuel Burghardt ihre interdisziplinäre Arbeit vor: „Patterns of Play: A Computational Approach to Understanding Game Mechanics”. Ziel dieser Arbeit ist es, anhand eines großen Datensatzes von Spielen Trends hinsichtlich der Beliebtheit von Spielen, ihrer Entwicklung im Laufe der Zeit und ihrer Beziehung zu den beliebtesten Spielgenres zu identifizieren, um die Methode für computergestützte Game Studies zu demonstrieren, ein Forschungsgebiet, das mich besonders interessiert.
Anschließend stellten Chen Jing und Paul Spence ein Case-Study zwischen China und Großbritannien über die transnationalen Verbindungen und Hindernisse in den Digital Humanities vor, in der wichtige Gemeinsamkeiten und Unterschiede hervorgehoben wurden, um uns zu helfen, die Herausforderungen besser zu verstehen, denen wir noch gegenüberstehen, um einen intensiveren internationalen Austausch zu fördern. Zum Abschluss dieses Blocks präsentierten Patricia Martín-Rodilla und Paloma Piot ihre Arbeit, in der sie Vorurteile in 13 verschiedenen Datensätzen aus der größten Meta-Sammlung von Hassreden analysierten und dabei die Bedeutung einer kritischen Untersuchung der von uns verwendeten Datensätze für die Digital Humanities hervorgehoben, um intrinsische Vorurteile zu vermeiden.
Fazit
Insgesamt habe ich durch den Besuch der verschiedenen Präsentationen gelernt, wie breit und vielfältig das Gebiet der Digital Humanities ist. Ich hatte die Möglichkeit, verschiedene Projekte und Forschungsinteressen zu erkunden und kennenzulernen und viele Menschen zu treffen, die ebenfalls ein Interesse an Wissen haben und für die der Austausch in diesem Bereich wichtig ist. Durch die Teilnahme an einer Panel-Diskussion konnte ich aus erster Hand erfahren, wie wichtig Diskussionen sind und wie viele unterschiedliche Standpunkte und Probleme es in den Digital Humanities noch gibt.
Durch die verschiedenen Präsentationen konnte ich auch die unterschiedlichen Methoden kennenlernen, mehr über sie erfahren und erleben, wie sie in vielen verschiedenen Fragestellungen eingesetzt werden können. Diese Erfahrung war wirklich interessant und ermöglichte es mir, in das Forschungsgebiet der Digital Humanities einzutauchen, Möglichkeiten zu entdecken und sogar eine Zukunft in diesem Bereich in Betracht zu ziehen, in dem ich meinen Platz finden kann, da die Vielfalt die Digital Humanities zu einer breiten und interessanten Disziplin macht.