Wir möchten Sie herzlich zur nächsten Veranstaltung unserer Werkstattreihe Standardisierung einladen: Jennifer Ecker, Pia Schwarz und Rebecca Wilm werden DeReKo vorstellen und freuen sich auf die Diskussion mit uns: https://events.gwdg.de/event/1024/.
DeReKo
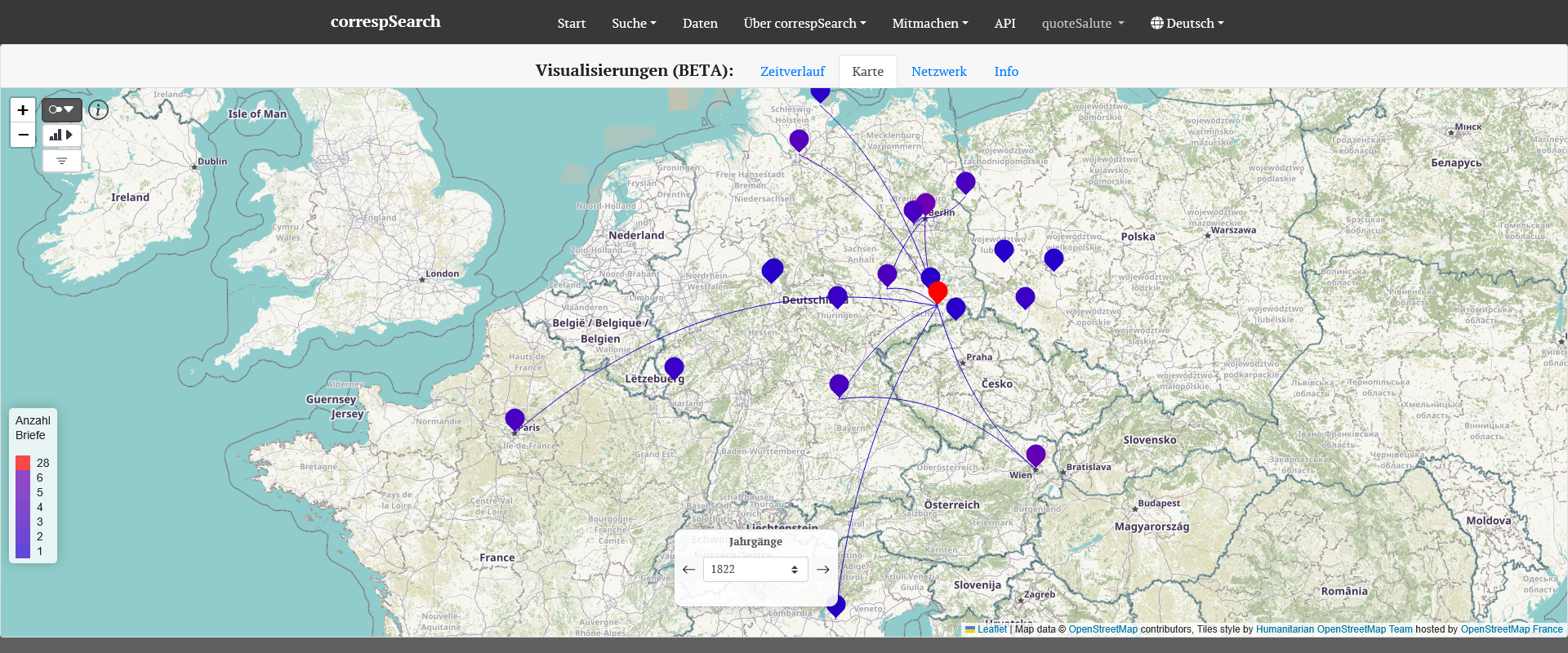
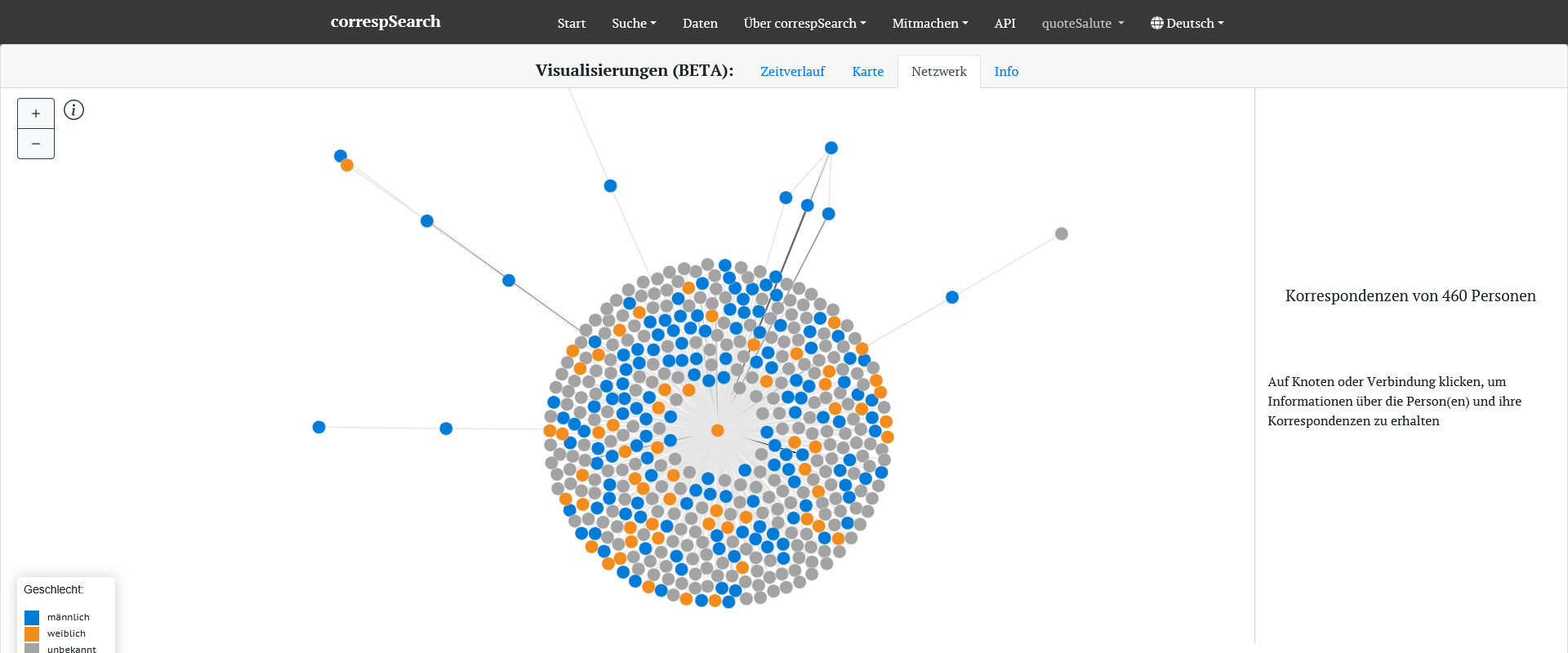
Das IDS beheimatet viele Daten und Tools für die Forschung mit insbesondere deutschsprachige Daten. Unter anderem besteht die Möglichkeit, große, annotierte Korpora zu durchsuchen, ein sehr prominentes Beispiel ist das Deutsche Referenzkorpus DeReKo, das mithilfe der Korpus-Analyseplatform KorAP genutzt, durchsucht und “beforscht” werden kann. Im Hintergrund müssen die Sprachdaten dafür in einem bestimmten TEI-Format vorliegen: In diesem Beitrag gehen wir auf TEI I5 ein, erläutern wie man mit welchen Tools eine Sprachdatensammlung in das notwendige Format umwandelt und so aufbereitet, dass sie am IDS als Korpus archiviert und in einem weiteren Schritt auch mit KorAP aufgerufen werden könnte.
Wir freuen uns auf den Vortrag durch unsere Kolleginnen Jennifer Ecker, Pia Schwarz und Rebecca Wilm. Bitte verteilt die Einladung gerne innerhalb eurer Kreise weiter.
Alle Termine der Werkstattreihe und die Anmeldungsmöglichkeiten finden Sie hier: https://events.gwdg.de/category/284/.
Und leiten Sie diese Einladung auch gern an andere Interessierte weiter.
Worum geht es in der Werkstattreihe Standardisierung?
Anhand konkreter Anwendungsbeispiele (https://text-plus.org/themen-dokumentation/standardisierung/anwendungsbeispiele/) erhalten die Teilnehmenden Einblicke in die Verwendung von Standards und standardisierten Tools und können an den Erfahrungen der Vortragenden in ihren jeweiligen Projekten teilhaben. Ziel ist es, ihnen so die Planung und Umsetzung ihrer Vorhaben zu erleichtern.
Darüber hinaus soll die Werkstattreihe Weichen für die zukünftige Datenintegrationen in die Text+ Infrastruktur stellen, die interne Reflektion über Angebotsentwicklung, Infrastruktur und Schnittstellen voranbringen sowie Partizipationsmöglichkeiten für Datengebende beleuchten. Die Reihe ist eine gemeinsame Aktivität aller Task Areas in Text+ in Zusammenarbeit mit Kolleginnen und Kollegen aus der Community.
Die Anwendungsbeispiele:
• 20. März: DTABf, Marius Hug, Frank Wiegand
• 11. April: correspSearch, Stefan Dumont
• 22. Mai: edition humboldt digital, Christian Thomas, Stefan Dumont
• 5. Juni: INSeRT, Felix Helfer, N.N.
• 17. Juli: PROPYLÄEN. Goethes Biographica, Martin Prell
• 18. September: DeReKo, Jennifer Ecker, Pia Schwarz, Rebecca Wilm
• 16. Oktober: Klaus Mollenhauer Ausgabe, Max Zeterberg
• 20. November: BERIA Collection, Isabel Compes, Felix Rau
Zielgruppe:
Die Reihe spricht ein breites Publikum mit Bezug zu Sprach- und Textwissenschaften an. Sie ist sowohl für Neulinge, die einen ersten Einstieg in das Thema finden möchten (z. B. Promovierende, Forschende ohne Infrastrukturanbindung), aber auch für im Einsatz von Standards und Tools Versierte, die von Erfahrungen aus ähnlichen Vorhaben profitieren möchten bzw. ebenfalls ihre Erfahrungen mitteilen möchten, gleichermaßen geeignet. Gerne darf diese Einladung also breit weiterverteilt werden.
Anmeldung:
Zur Anmeldung für die nächste Veranstaltung bitte hier entlang: https://events.gwdg.de/event/1024/.
Die Einladungen für die weiteren Veranstaltungen folgen. Es ist aber bereits auch jetzt möglich, sich für alle Veranstaltungen individuell anzumelden: https://events.gwdg.de/category/284/.

; CC-BY-4.0 / https://zenodo.org/records/8228540")