Gerne möchten wir Sie zum morgigen Online-Vortrag (16–18 Uhr (c.t.)) im Rahmen des TCDH-Forschungskolloquiums einladen:
Zita Baronnet (Universität Trier / TCDH): „Urheberrechtlich geschützte Texte online veröffentlichen: Ein Versuch, das Paradoxon zu lösen”
Wie kann man urheberrechtlich geschützte Texte online zugänglich machen, ohne gegen das Urheberrecht zu verstoßen? Wenn urheberrechtlich geschützte Texte als Klartext online verbreitet werden, wird das Urheberrecht verletzt. Andererseits sind komplett verschlüsselte Texte nutzlos für Forscher, da keine computergestützten Analysemethoden wie Sentiment Analysis auf ihnen verwendet werden können. Ziel des DFG-Projekts ‚Forschen mit Derivaten‘ – das im Vortrag vorgestellt wird – ist die Entwicklung eines Ansatzes, mit dem urheberrechtlich geschützte Texte online veröffentlicht und trotzdem analysiert werden können, ohne das Urheberrecht zu verletzen. Wir untersuchen verschiedene Methoden, von der Randomisierung bis zur homomorphen Verschlüsselung, um dieses Problem zu lösen.
Im Sommersemester 2026 setzen wir unsere Vortragsreihe im Rahmen des TCDH-Forschungskolloquiums fort. Das Spektrum reicht in diesem Semester von Fragen der digitalen Erschließung und Vernetzung historischer Texte und Wörterbücher über rechtliche und ethische Herausforderungen im Umgang mit Forschungsdaten bis hin zu digitalen Editionen und Plattformlösungen für die geisteswissenschaftliche Forschung.
Sie sind herzlich eingeladen, teilzunehmen und mitzudiskutieren!
Liebe WissKI-Community und alle die sich für Linked Open Data Management interessieren,
auch in diesem Jahr laden wir alle WissKI-Anwender*innen und -Entwickler*innen herzlich ein, um gemeinsam über Projekte und Themen zu diskutieren, sich über aktuelle Entwicklungen zu informieren und gemeinsam Lösungen für Herausforderungen zu entwickeln. Das 8. WissKI Anwender*innentreffen findet statt:
Bis zum 31. August 2026 können Beiträge in Form von Präsentationen und Workshops eingereicht werden. Eure Einreichungen werden dieses Jahr in einem Book of Abstracts veröffentlicht! Mehr dazu in unserem „Call for Abstracts“.
Eine Anmeldung zur Teilnahme am WissKI Anwender*innentreffen ist bis einschließlich 30. September 2026 möglich. Bei Fragen rund um das WissKI Anwender*innentreffen schreibt ihr an info@wiss-ki.eu oder in unseren Mattermost WAT Channel.
Das Dokument vergleicht und fasst gemeinschaftlich entwickelte Arbeitsdefinitionen der TWG zusammen. Ziel ist ein gemeinsamer begrifflicher und modellierungstechnischer Rahmen. Durch Klärung der Konzepte und Darstellung von Modellierungsstrategien (z. B. probabilistische Ansätze, graduelle semantische Abbildungen, Wikibase-Implementierungen) trägt die Arbeit zu transparenteren, interoperableren und FAIR-konformen Lösungen für unsichere, unpräzise oder mehrdeutige Informationen in Kulturerbe-Wissensgraphen bei.
Das Whitepaper kann im Rahmen des NFDI4Objects-Commons-Prozess bis 28. Mai 2026 kommentiert werden! Wir freuen uns auf Euer Feedback!
Der Webservice correspSearch, der historische Briefe durchsuchbar macht und vernetzt, hat einen wichtigen Meilenstein erreicht. Mit der jüngsten Integration der Briefe an Helmina von Chézy, die durch ein Explorationsprojekt an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) ermöglicht wurde, weist die Plattform nun mehr als 400.000 Metadatensätze von edierten oder wissenschaftlich erschlossenen Briefen nach.
Initiiert von der BBAW-Arbeitsgruppe „Gender & Data“ und mit institutioneller Unterstützung der Akademie wird seit 2025 an der Erschließung der Korrespondenzen in Helmina von Chézys Nachlass im Akademiearchiv gearbeitet (Mitwirkende s. u.). Innerhalb von acht Monaten wurde die umfangreiche Korrespondenz von rund 3.500 Briefen mit Unterstützung von TELOTA und unter Nutzung des CMIF Creators erfasst und für die Aufnahme in correspSearch vorbereitet. Etwa 2.000 Briefe wurden an Chézy gerichtet und knapp 1.400 von ihr verfasst. Erstere sind nun freigeschaltet, die Briefe von Chézy selbst werden in Kürze ebenfalls integriert. Zukünftig sollen die Informationen auch zurück in das Findbuch des BBAW-Archivs fließen, um die Nutzung der Bestände vor Ort zu verbessern.
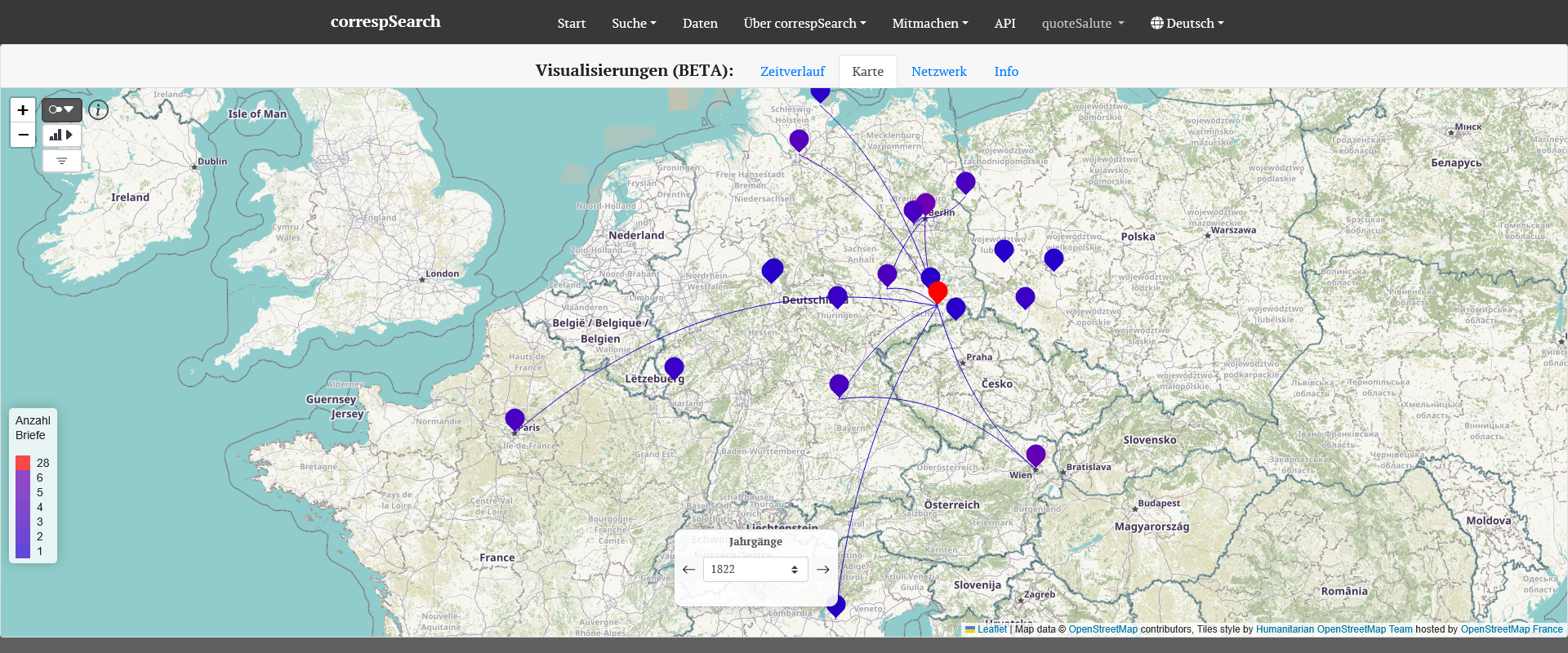
Helmina von Chézy (1783–1856) war als Schriftstellerin, Journalistin und Intellektuelle in vielfältige Netzwerke eingebunden. Mit rund 20 Jahren ging sie nach Paris und verbrachte dort ein prägendes Jahrzehnt, in dem sie Kontakte zu den Romantikern Dorothea und Friedrich Schlegel knüpfte und journalistisch für französische und deutsche Zeitschriften arbeitete. Ein besonderes Kapitel stellte ihr humanitäres Engagement 1815/16 dar, als sie in Lazaretten in Köln und Namur verwundete Soldaten pflegte. Ihr kritischer Bericht über deren schlechte Behandlung führte zu einer Gefängnisstrafe, vor der sie nach Berlin floh, wo E. T. A. Hoffmann erfolgreich ihre Verteidigung übernahm. Ihre Dresdner Jahre (1817–1823) markierten einen Höhepunkt ihres Schaffens durch die Mitgliedschaft im Dresdner Liederkreis und die Zusammenarbeit mit Carl Maria von Weber am Libretto zur Oper „Euryanthe“.
Helmina von Chézys Korrespondenz bildet den zentralen Bestandteil ihres Nachlasses. Rund 3.500 Briefe dokumentieren ein weitreichendes Netzwerk aus Personen aus Literatur, Kunst, Politik und Verlagswesen. Die Briefe geben Einblick in literarische Arbeitszusammenhänge und soziale Beziehungen und zeigen zugleich die Lebensbedingungen einer Frau, die sich im frühen 19. Jahrhundert in einem überwiegend männlich geprägten kulturellen Umfeld behauptete. Ein nicht unerheblicher Teil der Korrespondenz entfällt auf den Austausch mit Frauen und verweist auf die Bedeutung weiblicher Netzwerke in dieser Zeit.
Helmina von Chézys internationales Briefnetzwerk im Jahr 1822 während ihres Aufenthalts in Dresden. [Screenshot der Visualisierung in correspSearch]
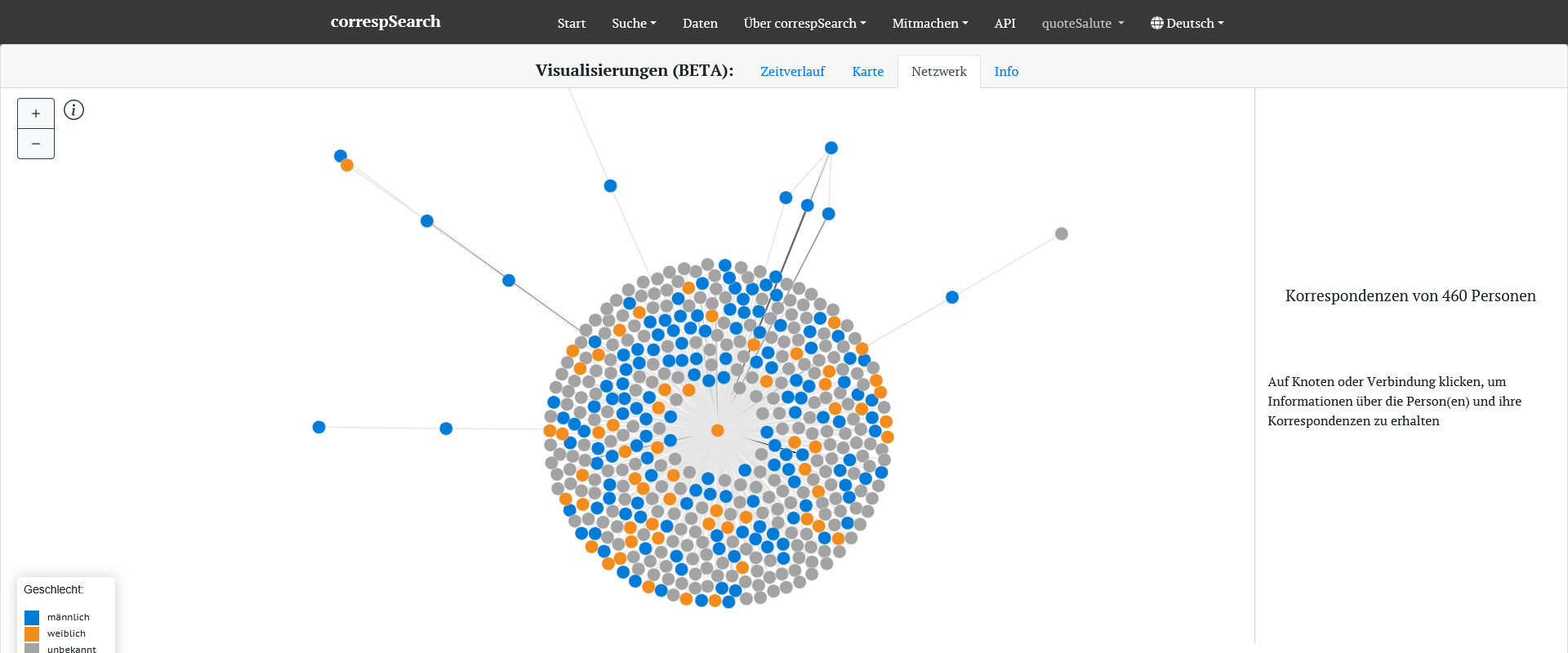
Netzwerk der an Helmina von Chézy gerichteten Briefe mit farblicher Kennzeichnung des Geschlechts der Briefpartner. Graue Punkte markieren Personen ohne Normdaten, für die bislang keine Geschlechtsinformation vorliegt. [Screenshot der Visualisierung in correspSearch]
Aktiv gegen den Gender-Data-Gap
Wie in vielen anderen digitalen Diensten und Sammlungen besteht auch in correspSearch ein deutlicher Gender-Data-Gap. Dieser geht zum Teil auf historisch bedingte Ungleichheiten zurück, wird jedoch durch Überlieferungsbrüche und -lücken sowie eine häufig unzureichende Erschließung vorhandener Bestände weiter verstärkt.
Die systematische Aufarbeitung von Nachlässen wie dem Helmina von Chézys trägt dazu bei, Frauen als historische Akteurinnen im digitalen Raum sichtbarer zu machen und eröffnet neue, auch geschlechtergeschichtliche Perspektiven für die Forschung. Dieses Anliegen wird an der BBAW seit April 2026 von einer auf zwei Jahre geförderten Initiative „Gender & Data“ weitergeführt, die sich unter anderem mit der Rolle der Digital Humanities für eine inklusivere geisteswissenschaftliche Forschung befasst.
***
Mitwirkende an der Erschließung des Chézy-Nachlasses: Michael Rölcke (Bearbeiter), Bénédicte Savoy und Frederike Neuber (Leitung, Herausgeberschaft), Stefan Dumont und Steven Sobkowski (correspSearch), Sandra Miehlbradt (BBAW-Archiv).
Ein partizipativer Workshop der Initiative „Datenzentrum – wissenschaftliche Konzeption und Ausgestaltung“ der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW)
Berlin, 25. und 26. Juni 2026; Akademiegebäude am Gendarmenmarkt; Einstein-Saal
Der Wert geisteswissenschaftlicher Forschungsdaten für Wissenschaft und Gesellschaft ist nicht zuletzt durch den laufenden Aufbau der Nationalen Forschungsdateninfrastruktur (NFDI) offensichtlich geworden. Zentrale Fragen nach dem dauerhaften Betrieb vertrauenswürdiger Datenrepositorien und der langfristigen Verfügbarkeit der aggregierten Inhalte sind jedoch weiterhin offen.
Vor diesem Hintergrund lädt die Initiative „Datenzentrum – wissenschaftliche Konzeption und Ausgestaltung“ der BBAW zu einem zweitägigen Lunch-to-Lunch-Workshop ein. Diese 2025 eingerichtete Initiative erarbeitet ein Konzept für die organisatorischen und technischen Grundlagen für ein leistungsfähiges, zertifiziertes Repositorium und dessen infrastrukturelle Einbindung innerhalb der BBAW. Darauf aufbauend wird die Akademie ab 2028 ein eigenes Datenzentrum betreiben. Dessen Hauptaufgaben werden die Aggregation, Verfügbarhaltung und Archivierung von Forschungsdaten, Software und Diensten aus den Vorhaben und Projekten der Akademie sein. Darüber hinaus ist eine Öffnung des Repositoriums für externe Datengeber:innen vorgesehen.
Im Workshop werden anhand von Impulsvorträgen die unterschiedlichen Perspektiven aus Sicht von Forschung, Bibliothek, Archiv und IT reflektiert. Anschließend bieten verschiedene Thementische die Möglichkeit zu einer intensiven Auseinandersetzung mit spezifischen Fragen, von der technischen Einrichtung nachhaltiger Infrastrukturen zwischen quelloffenen und kommerziellen Lösungen bis hin zum Einsatz sog. Künstlicher Intelligenz samt deren ethischen Herausforderungen.
Das vierte Community Meeting 2026 von NFDI4Objects findet virtuell statt! Die Veranstaltung richtet sich an Einsteiger:innen und Interessierte und bietet spannende Einblicke in die Arbeit des Konsortiums. Freut euch auf interaktive Formate, Austauschmöglichkeiten und dezentrale Online-Workshops.
Programm und Workshop-Termine folgen in Kürze – merken Sie sich den Termin schon jetzt vor!
Hiermit laden wir Euch sehr herzlich zum nächsten Clustertreffen des CC „Authority Files and Community-driven Vocabularies“ am 29. April 2026, von 13 bis 14:30 Uhr, ein. Dieses Mal wird es ein Hands on für DANTE mit unserem Chair Michael Markert von der VZG geben.
DANTE ist ein Webservice zur Pflege und Veröffentlichung von Vokabularen, der von der Verbundzentrale des GBV auch für NFDI4Objects-Institutionen bereitgestellt wird. Zu unserem Hands-On-Treffen wollen wir gemeinsam Datensätze im DANTE-Testpool anlegen und bearbeiten, damit neue Nutzer:innen sich mit der Funktionalität vertraut machen können.
Bringt gern Beispieldaten aus dem Bereich Personen, Körperschaften, Orte und Sachbegriffe zum Ausprobieren mit!
Es wäre schön, wenn auch erfahrene DANTE-Nutzer:innen zur Unterstützung bei Fragen dabei sein könnten.
Am Dienstag, 28. April 2026 von 9 bis 11 Uhr findet die nächste Sitzung des Community Clusters Protected Heritage Sites online statt.
Themen der Sitzung sind:
Abschluss: Datenmodelle für Maßnahmenobjekte und Schutzflächen
Voraussichtlich wird dies die letzte Sitzung sein, in der die Modelle Thema sind. Falls Sie keine Zeit haben, an dem Treffen teilzunehmen, schicken Sie daher gerne Ihre Anmerkungen per E-Mail, damit sie in der Diskussion berücksichtigt werden können.
Das Protokoll der 15. Sitzung des CC Protected Heritage Sites vom 12.03. ist ab sofort via OSF verfügbar: https://osf.io/pwzg4/. Hier finden Sie auch die aktuellen Entwürfe der Datenmodelle.
Im Rahmen des Community Clusters Data Capture and Creation findet am 12. Mai 2026 von 14:30-16:00 Uhr die Vorstellung der App und Datendrehscheibe Fund-Logbuch statt. Die im Aufbau befindliche Infrastruktur bietet eine digitale Lösung für die Erfassung archäologischer Kleinfunde in der Citizen Science. Sie soll sicherstellen, dass Neufunde zukünftig schneller und ohne Umwege in Forschung und Denkmalschutz einfließen und Citizen-Science-Daten in der Archäologie sichtbarer werden. Die Präsentation beinhaltet eine Live-Demonstration der bereits als Prototyp existierenden App in einem realen Anwendungsszenario.
Unsere vortragenden Kolleg:innen Niels Cederstrom (Dataport AöR) und Johanne Lefeldt (GDKE) freuen sich auf den Austausch mit Euch.
Vom Inventar zum Knowledge Graph – Objektdokumentation im Wandel der Zeit am Beispiel der Berliner Kunstkammer und ihrer Nachfolge-Institutionen von Diana Stört und Sarah Wagner
Die Objektbestände der Berliner Kunstkammer bilden heute die Grundlage der Sammlungen der Staatlichen Museen zu Berlin, der Humboldt-Universität zu Berlin sowie des Museums für Naturkunde Berlin. Durch diese historische Verbindung ergibt sich eine Dokumentationspraxis von über 400 Jahren, deren Erforschung sich Diana Stört und Sarah Wagner widmen. Sie befassen sich mit der Frage, wie sich die Praktiken und Medien in ihrer Funktion und Struktur in einem sich wandelnden disziplinären Kontext veränderten und welche Rückschlüsse sich daraus auf die aktuelle Dokumentations- und Digitalisierungspraxis ziehen lassen. Dabei spielen Semantic Web Technologien, Knowledge Graphen und das Konzept der Objektbiografie eine zentrale Rolle, die auch für die Erzeugung und Integration von Daten bei NFDI4Objects grundlegend sind.
In einem DFG-Projekt wurden die Bestände der Berliner Kunstkammer unter Anwendung des Konzepts der Objektbiografie ausgehend von Quellenmaterialien digital auf Grundlage des CIDOC CRM in einer WissKI-basierten Forschungsumgebung erschlossen. Der Datensatz mit über 2000 Objekten sowie zugehörigen Quellen-, Akteur- und Ortsinformationen wurden daher in den Wissensgraphen der NFDI4Objects integriert, wo die Objekte nun neue Verbindungen eingehen können.
Ab März 2026 findet eine gemeinsame Sprechstunde zum Forschungsdatenmanagement der vier Humanities@NFDI-Konsortien (NFDI4Memory, NFDI4Culture, NFDI4Objects und Text+) statt.
Sie richtet sich an Studierende, Forschende sowie Mitarbeitende aus Forschungs- und Sammlungsinstitutionen und bietet Raum für Fragen rund um das Forschungsdatenmanagement.
Am 17.03.2026 von 9:00–10:00 Uhr findet die erste Online-Sprechstunde statt. Die Teilnahme ist auch ohne Anmeldung über Zoom möglich.
Einmal im Monat stehen künftg Expert:innen aus den beteiligten NFDI-Konsortien für Fragen bereit. Bei Bedarf können Themen auch in Breakout-Räumen im Einzelgespräch vertieft werden. Eine Terminübersicht für 2026 findet sich auf der Humanities@NFDI-Unterseite.
Bei dringenden Fragen können Sie sich jederzeit auch an die Helpdesks wenden:
Die Konzepte des Datenlebenszyklus und der Objektbiografie bilden die zentrale konzeptionelle Grundlage von NFDI4Objects. Während der Datenlebenszyklus mit seinen Phasen von Datenerstellung über Verarbeitung, Analyse, Veröffentlichung bis hin zur Archivierung ein etabliertes Prinzip im Forschungsdatenmanagement darstellt, eröffnet die Objektbiografie einen neuen Zugang zur Erzeugung, Modellierung und Repräsentation von Sammlungsdaten.
Die Objektbiografie versteht Objekte nicht als statische Einheiten, sondern als dynamische Knotenpunkte, die im Laufe ihrer Existenz mit unterschiedlichen Ereignissen, Akteur:innen, Orten und Bedeutungen verknüpft sind. Sie integriert historische, archäologische, naturwissenschaftliche und museale Perspektiven und schafft damit einen interdisziplinären Rahmen zur Beschreibung materieller Kultur.
Als Paradigma zur Datenmodellierung geht die Objektbiografie über einen rein narrativen Ansatz hinaus. Sie ermöglicht es, die Semantik materieller Kultur systematisch in digitale Wissenssysteme zu überführen und komplexe Objektzusammenhänge strukturiert abzubilden.
Zu diesem Ansatz haben Anja Gerber und Sarah Wagner ein Positionspapier vorgelegt, das Anfang Januar auf Zenodo veröffentlicht wurde. Das Papier erläutert die theoretischen Grundlagen der Objektbiografie und zeigt ihre Bedeutung für die Weiterentwicklung von Sammlungs- und Forschungsdaten im Kontext von NFDI4Objects auf.
Die Publikation wird von den AG-Mitgliedern Anja Gerber (KSW | NFDI4Objects) und Dr. Domenic Schäfer (VZG | NFDI4Culture, LIDO-Servicestelle) vorgestellt. Die Präsentation widmet sich der zentralen Rolle kontrollierter Vokabulare und Normdaten für eine nachhaltige Nachnutzbarkeit objektbeschreibender Daten in Museen und Sammlungen.
Ausgehend von den Empfehlungen der Minimaldatensatz-Empfehlung für Museen und Sammlungen wurde eine systematische Zusammenstellung einschlägiger Vokabulare für die Sammlungsdokumentation erarbeitet. Vorgestellt werden unter anderem:
inhaltliche Schwerpunkte der jeweiligen Vokabulare,
ihr technischer Implementierungsstand sowie
eine Bewertung nach den FAIR-Prinzipien.
Die Einstufung nach FAIR-Kriterien ermöglicht eine fundierte Einschätzung der Nachhaltigkeit und Nachnutzbarkeit der Vokabulare, insbesondere im Kontext des vernetzten Publizierens und eines effektiven Forschungsdatenmanagements.
Die zugrunde liegende Publikation ist bereits auf Zenodo verfügbar.
Am Donnerstag, 19. März 2025, 15 Uhr (MEZ), lädt das Community Cluster „Objekte als Inschriftenträger” von NFDI4Objects zu einem Treffen mit Vortrag ein.
Thema wird die Modellierung von Inschriften sein, die in der Ontologie des FAIR Epigraphy Project entwickelt wurde. Wir freuen uns, dass Jonathan Prag und Imran Asif (Oxford) uns diese Arbeit vorstellen werden: ‘A CIDOC-based ontology for Epigraphy: mapping the epigraphic datasphere’
Die Integration von Daten aus verschiedenen digitalen Epigraphik-Projekten ist seit langem ein Desiderat und wurde für die griechisch-römische Epigraphik im Rahmen des EAGLE-Projekts (2012-2016) pilotiert. Das FAIR Epigraphy Project (AHRC-DFG, 2023–2026) verfolgt einen semantischen Webansatz für dieses Problem und entwickelt Tools und Standards zur Erleichterung der Datenintegration (siehe https://inscriptiones.org/). Dieser Ansatz basiert auf der Annahme, dass die Serialisierung in RDF eine sinnvolle Lösung für das allgemeine Problem darstellt, insbesondere angesichts der Vielfalt der derzeit verwendeten Ansätze zur Datendigitalisierung. Anknüpfend an frühere Versuche, eine Ontologie für die Epigraphik zu entwickeln, darunter die CRMtex-Erweiterung zu CIDOC, haben wir eine vorläufige Ontologie auf der Grundlage von CIDOC-CRM entwickelt, die unserer Meinung nach fast den gesamten epigraphischen Datenbereich abdeckt, von Objekten und Texten bis hin zu deren Reproduktion, Untersuchung und Veröffentlichung.
Jonathan Prag ist Professor für Alte Geschichte am Merton College in Oxford. Er ist Experte für Sizilien in der hellenistisch-römischen Zeit und hat umfangreiche Arbeiten auf diesem Gebiet durchgeführt, unter anderem zu Inschriften und der Übertragung epigraphischer Informationen in das Semantische Web.
Imran Asif ist leitender Forschungssoftwareentwickler am Centre for the Study of Ancient Documents in Oxford und verantwortlich für die technische Umsetzung der digitalen Epigraphik im Rahmen des FAIR Epigraphy Project.
Im Rahmen des Projektes GND4C wurden teilautomatische Workflows zur Batch-Einspielung von Daten in die GND entwickelt, woran auch die Thüringer Universitäts- und Landesbibliothek in Jena beteiligt war. Michael Marchert hat in diesem Projekt Thüringer Kirchenbauten mit Hilfe von Python-Skripten und OpenRefine in Abstimmung mit den GND-Gremien für eine Einspielung vorbereitet. Er wird von seinem Vorgehen und den damit verbundenen Herausforderungen berichten.
Am 10. März 2026 findet 14:30 bis 16:00 Uhr das Clustertreffen des N4O CC Data Capture and Creation mit Sophie Döring (Institut für Historische Landesforschung der Universität Göttingen, vormals Institut für Sächsische Geschichte und Volkskunde) zum Thema Ortsdaten statt.
Historische Ortslexika sind sowohl Grundlagenwerke (landes)geschichtlicher Forschung als auch zentrale Hilfsmittel zur Kuration von Datenobjekten in Museen oder Bibliotheken sowie ein wichtiges Recherchewerkzeug einer breiten interessierten Öffentlichkeit und Citizen-Science-Projekten. Während es in Sachsen, Hessen, Baden-Württemberg und Bayern bereits eigene öffentlich finanzierte digitale Datenbanken zur Erfassung und Verwaltung historischer Ortsdaten gibt, fehlen im restlichen Bundesgebiet bislang entsprechende Repositorien. Dieser Umstand erschwert nicht nur die historische Recherchearbeit in Archiven, sondern auch die präzise Zuordnung von historischen Dokumenten, Objekten und Entwicklungen sowie die Nachnutzbarkeit bereits vorhandener Daten. Unter anderem liegt die Problematik auch in einer bis heute kaum standardisierten Aufnahme, Verarbeitung und Systematisierung historischer Ortsdaten begründet, welche besonders kleinere Projekte ohne eigentlichen Schwerpunkt auf historische Ortsdaten vor enorme Schwierigkeiten stellen.
Dieser Fehlstelle nimmt sich der Minimaldatensatz Historische Ortsdaten an, welcher derzeit von der AG Historische Ortsdaten konzipiert und erprobt wird. Er benennt und erläutert Informationen und Datenfelder, die zwingend notwendig sind, um historische Daten zu Siedlungsplätzen in einer nachhaltigen, eindeutigen, leicht auffindbaren und austauschfähigen Art und Weise zu kuratieren und zu publizieren. Damit wird in einfacher Form das minimal notwendige Maß an Datenqualität, welches in der Verwaltung von Ortsdaten erfüllt sein sollte, sowohl für größere als auch kleinere Projektkontexte strukturiert.
Es ist keine Anmeldung erforderlich, wir freuen uns über Ihre / Eure Teilnahme und auf den gemeinsamen Austausch.
heute startet die Bewerbungsphase für den Zertifikatskurs Forschungsdatenmanagement, der im September 2026 zum sechsten Mal beginnt. Eine Bewerbung ist ab sofort bis zum 27. April 2026 möglich.
Über den Zertifikatskurs Forschungsdatenmanagement:
Der Kurs bietet die einzigartige Möglichkeit, Kompetenzen zum FDM und deren Anwendung in Service-Bereichen an Hochschulen und Forschungseinrichtungen berufsbegleitend, systematisch und zertifiziert zu erwerben. Er richtet sich an Beschäftigte aus wissenschaftsnahen Infrastruktur-Bereichen sowie aus der Forschung und umfasst die Themenbereiche: Forschungsdaten-Lebenszyklus, Datentypen, Forschungsprozesse in verschiedenen Fachgebieten, Open Science, Hacken und Experimentieren mit Daten, Forschungsprojektmanagement, technische Infrastruktur für Repositorien, Metadaten, nachhaltiges Datenmanagement, relevante rechtliche Aspekte sowie Ansätze zur Beratung und Vermittlung von FDM-Themen für verschiedene Zielgruppen.
Der Zertifikatskurs Forschungsdatenmanagement ist eine Kooperation der TH Köln, des ZBIW, der Landesinitiative für Forschungsdatenmanagement – fdm.nrw und ZB MED – Informationszentrum Lebenswissenschaften und wird seit 2021 für Interessierte aus Nordrhein-Westfalen und seit 2023 deutschlandweit angeboten.
Was euch erwartet: Hands-on-Sessions: Praktisches Arbeiten mit Euren eigenen Datensätzen Vertiefung spezifischer LLM-Themen und Anwendungsfälle Kollegialer Austausch, Peer-Feedback und gezielte fachliche Unterstützung
Expertinnen: Sarah Oberbichler (C²DH), Johanna Mauermann (IEG DH Lab | HERMES), Lauren Coetzee (C²DH)
In verschiedenen Impulsvorträgen und Hands-on-Sessions lernen Teilnehmende, wie sie offene, auf die geisteswissenschaftliche Forschung spezialisierte und lokale Modelle mit ihren eigenen Daten verwenden können und wie sie Prompts an geisteswissenschaftliche Fragen anpassen können. Ebenfalls reflektieren wir, wie Daten für ein Fine-Tuning oder Post-Training eines kleinen Sprachmodells aufbereitet werden können.
Voraussetzungen:
Der Workshop richtet sich an Forschende der Geisteswissenschaften, die mit Textdaten arbeiten. Vorausgesetzt werden grundlegende Kenntnisse im Bereich generativer KI. Die mitgebrachten Daten sollten maschinenlesbar vorliegen.
Wir werden in manchen Hands-on-Sessions mit Jupyter Notebooks und Python sowie mit Hugging Face arbeiten. Die Teilnahme ist auch ohne vertiefte Kenntnisse in diesen Bereich möglich. Selbstlernmaterial zur Vorbereitung wird angeboten.
Kontrollierte Vokabulare und Normdaten spielen für die Nachnutzbarkeit von objektbeschreibenden Daten in Museen und Sammlungen eine zentrale Rolle. Die Minimaldatensatz-Empfehlung für Museen und Sammlungen enthält hierzu bereits wichtige Empfehlungen zur Anwendung von Terminologien in Kernelementen der Objektdokumentation.
Dieser Report stellt eine Reihe von einschlägigen Vokabularen für die Sammlungsdokumentation vor und bezieht dabei auch Angebote ein, die sich für bestimmte Dokumentationsschwerpunkte und Disziplinen eignen. Neben einer Kurzbeschreibung der jeweiligen inhaltlichen Schwerpunkte und dem technischen Implementierungsstand der Webangebote erfolgt jeweils eine Einstufung nach den Kriterien der international anerkannten FAIR-Prinzipien. Dies ermöglicht Mitarbeiter:innen in Museen und Sammlungen wie auch den Nachnutzenden der so ausgestatteten Datenbestände eine fundierte Beurteilung der Nachhaltigkeit der beschriebenen Vokabulare in Kontexten des vernetzten Publizierens und eines effektiven Forschungsdatenmanagements.
Diese Arbeit wurde von einer Unter-AG der AG Minimaldatensatz der Fachgruppe Dokumentation im Deutschen Museumsbund (DMB) erstellt. Ihre Mitglieder sind Mitarbeiter:innen bzw. Vertreter:innen der Deutschen Digitalen Bibliothek, der Humboldt-Universität zu Berlin (Koordinierungsstelle für wissenschaftliche Universitätssammlungen in Deutschland), des Instituts für Museumsforschung, der Klassik-Stiftung Weimar, der Ludwig-Maximilians-Universität München, der Philipps-Universität Marburg (Deutsches Dokumentationszentrum für Kunstgeschichte – Bildarchiv Foto Marburg) und der Verbundzentrale des Gemeinsamen Bibliotheksverbunds Göttingen (VZG).
Das NFDI-Konsortium Text+ lädt ein zum Workshop „Sprach- und Textdaten für Gesellschaft, Gesundheit und Medizin“ am 05.-06.03.2026 am Hamburger Zentrum für Sprachkorpora (HZSK). Der zweitägige Workshop (Lunch-to-Lunch) der TaskArea „Collections“ widmet sich den Schnittstellen zwischen sprach- und textbasierten Forschungsdaten und angrenzenden Disziplinen in den Bereichen Gesellschaft, Gesundheit und Medizin. Gemeinsam wollen wir erkunden, wie sich Forschungsdatenmanagement (FDM) für text- und sprachbasierte Forschung in diesen interdisziplinären Kontexten gestalten lässt.
Text+ ist ein Konsortium der Nationalen Forschungsdateninfrastruktur (NFDI) und hat zum Ziel, sprach- und textbasierte Forschungsdaten langfristig zu erhalten und ihre Nutzung in der Wissenschaft zu ermöglichen. Der Workshop bietet ein Forum für den Austausch über nachhaltige und sichere Bereitstellung, Analyse und Nachnutzung von Forschungsdaten. Dabei geht es u.a. um Fragen der mehrsprachigen Kommunikation und Multimodalität.
Programm-Highlights:
Keynotes und Fachvorträge zu aktuellen Herausforderungen und Lösungen im FDM für sprach- und textbasierte Forschungsdaten mit dem Fokus auf die Bereiche Gesellschaft, Gesundheit und Medizin
Posterpräsentationen und Demos: Teilnehmende sind eingeladen, eigene Ansätze und Projekte vorzustellen
Möglichkeiten der Erschließung weiterer Sprach- und Textdaten sowie deren Integration in Text+ und NFDI4Health
Zielgruppe:
Forscherinnen und Forscher aus den Geistes-, Sozial- und Lebenswissenschaften sowie alle, die sich für sprach- und textbasierte Daten in interdisziplinären Kontexten interessieren.




 19.–20. März 2026 (Do, 10:00 bis Fr, 16:00)
19.–20. März 2026 (Do, 10:00 bis Fr, 16:00) Präsenz-Workshop:
Präsenz-Workshop:  Hands-on-Sessions: Praktisches Arbeiten mit Euren eigenen Datensätzen
Hands-on-Sessions: Praktisches Arbeiten mit Euren eigenen Datensätzen Vertiefung spezifischer LLM-Themen und Anwendungsfälle
Vertiefung spezifischer LLM-Themen und Anwendungsfälle Kollegialer Austausch, Peer-Feedback und gezielte fachliche Unterstützung
Kollegialer Austausch, Peer-Feedback und gezielte fachliche Unterstützung