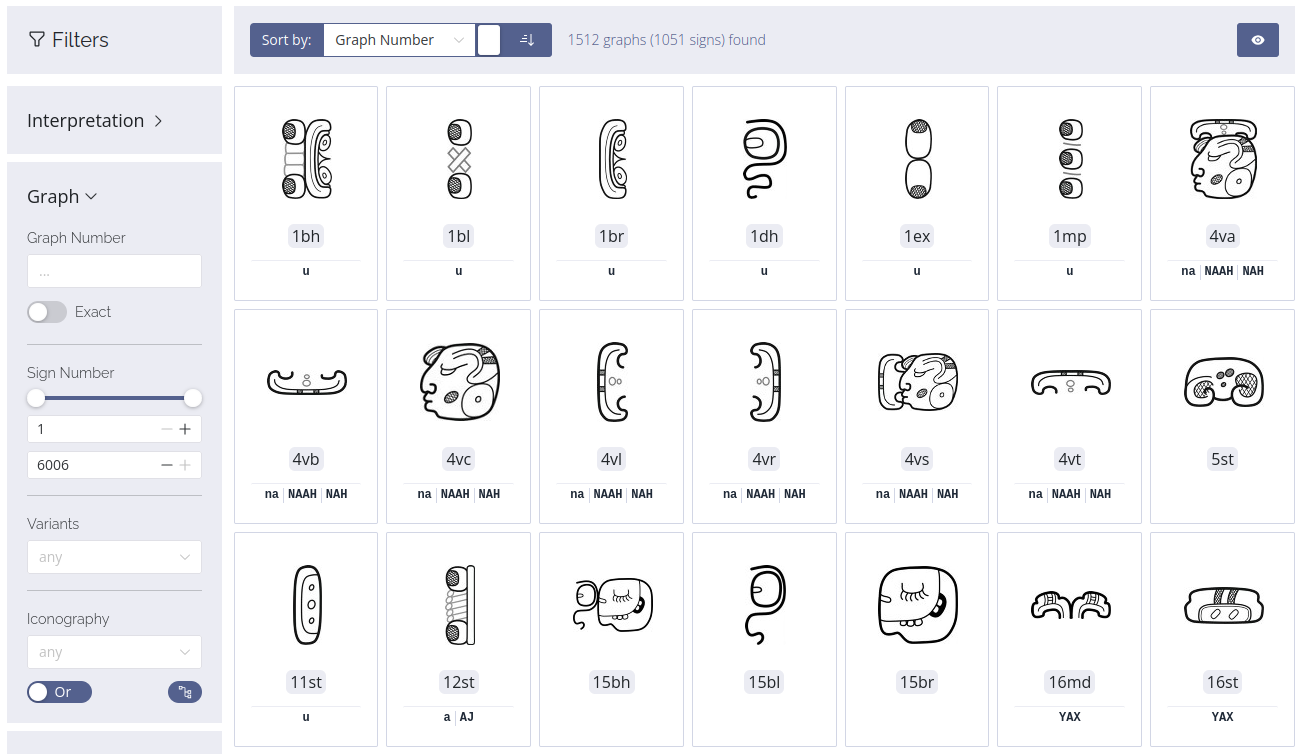
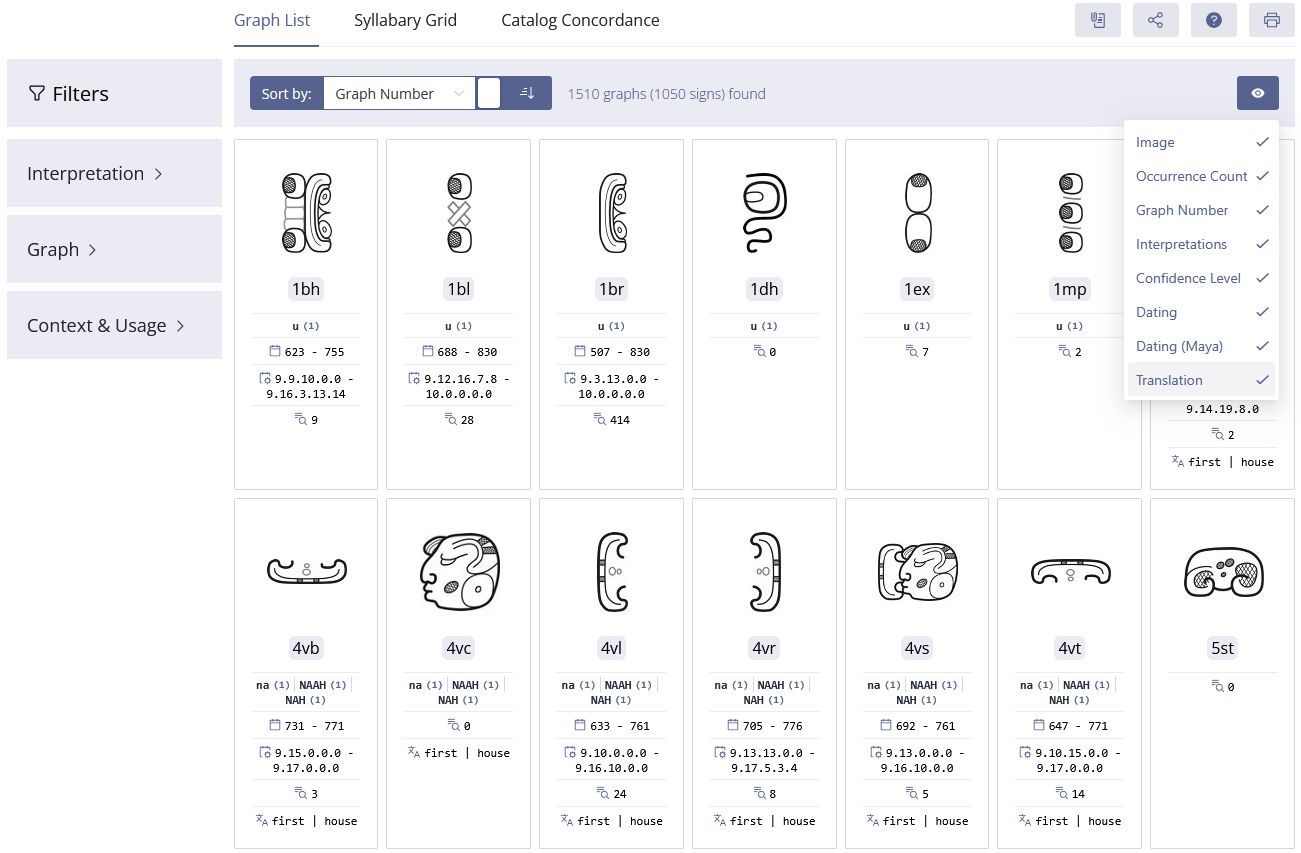
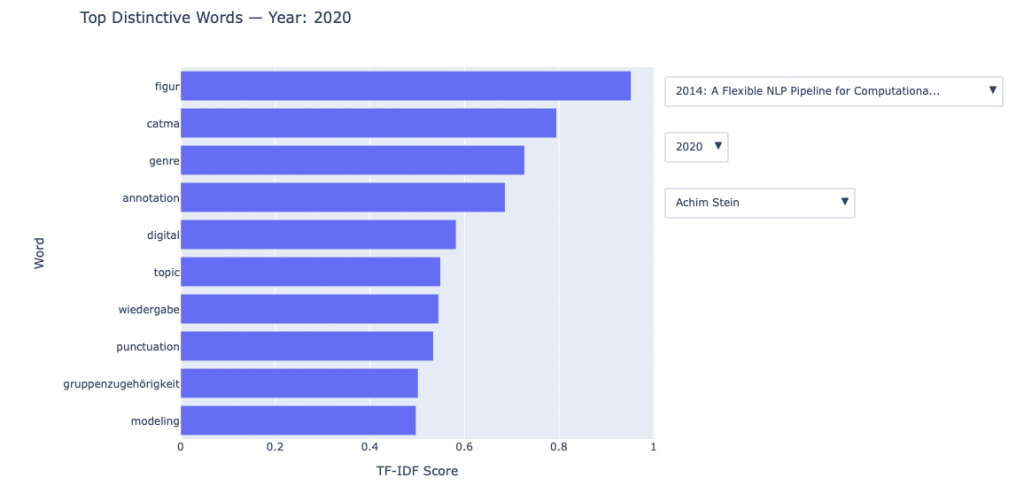
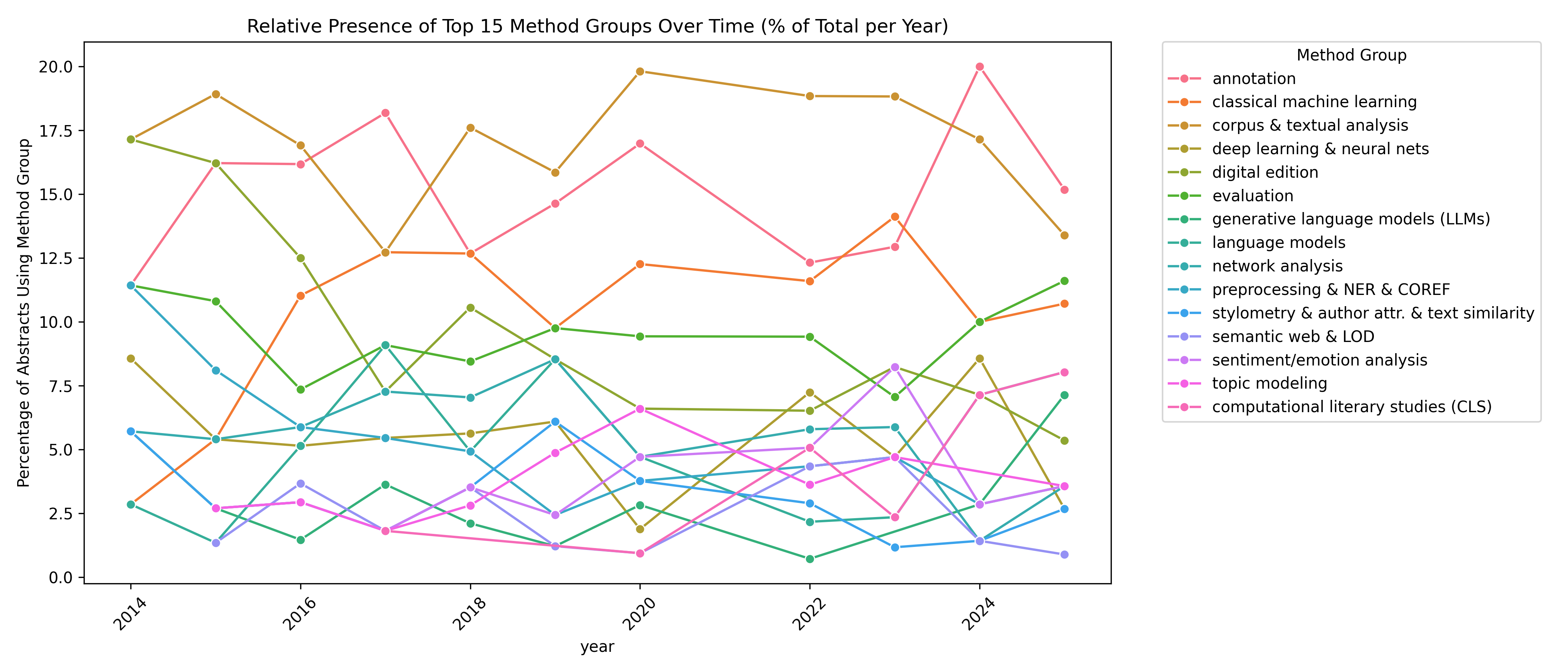
Kollaborationen der Mittelalterforschung im digitalen Zeitalter
Themenheft 2025/1 von Das Mittelalter
Im Namen der Herausgeberinnen und des DFG Netzwerks „Offenes Mittelalter“.
Der Begriff der Schnittstelle
Die Mediävistik ist ein per definitionem interdisziplinär ausgerichtetes Fachgebiet. Aufgrund ihrer
heterogenen, oftmals fragilen und nicht leicht zugänglichen Forschungsgegenstände und ihrer
besonderen Anforderungen haben sich Mediävist*innen schon früh der Möglichkeiten des Com-
puters bedient und sich damit als Pionier*innen der digitalen Geisteswissenschaften erwiesen.
Eine Vielzahl geisteswissenschaftlich-kultureller Praktiken blickt auf Vorläufer und Vorbilder aus
dem Mittelalter zurück, aus philologischer Tradition zählen hierzu etwa Übersetzungshilfen, The-
sauri, Konkordanzen und Annotationen. Die adäquate Darstellung der Quellen und ihre Erfahr-
barkeit im digitalen Raum sind besondere Herausforderungen, für die die Mediävistik Lösungen
entwickeln muss. Wegen der Vielfalt der Forschungsgegenstände, ihrer Historizität und ihrer
kulturhistorischen Bezugssysteme handelt es sich dabei um hochgradig interdisziplinäre Aufga-
ben. Computergestützte Ansätze und digitale Praktiken erweitern das Methodenspektrum und
schaffen neue Möglichkeiten eines nachhaltigen und vernetzten Wissensfundus. Die Mediävistik
hat in den letzten Jahren viele Ressourcen digital aufbereitet und von den technischen Möglich-
keiten profitiert, etwa im Bereich der Editionsphilologie zur Darstellung synoptischer Editionen
oder der Einbindung von Digitalisaten. Doch zumeist bleiben die erarbeiteten Mittel Insellösun-
gen. Nur in Ansätzen wurden theoretische Überlegungen entwickelt, wie einzelne Projekte mit-
einander verbunden werden können.
Das Themenheft „Schnittstelle Mediävistik“ widmet sich der computationell arbeitenden Mittel-
alterforschung in ihrer verbindungsstiftenden Funktion. Als Schnittstelle vermittelt sie zwi-
schen den Disziplinen, Digitalem und Analogem, heterogenen Forschungsgegenständen und
vielfältigen Methoden. Dabei integriert sie nicht nur Ansätze und Wissen aus anderen Fachbe-
reichen, sondern trägt auch zum Erkenntnisgewinn über ihre eigene Disziplin hinaus bei, indem
etwa Daten zu Handschriften für historische Netzwerkforschung oder Geovisualisierungen wei-
tergenutzt werden.
Das Themenheft adressiert Interdisziplinarität auf zwei Seiten: auf der Seite der Forschungs-
gegenstände, die abhängig von den Fachdisziplinen z. B. historische Daten, literarische Texte,
philologische Themen, Schrift- und Bild-Zusammenhänge und anderes untersuchen; auf der
Seite der Herangehensweisen, die je nach Fachdisziplinen ‚traditionelle‘ Arbeitsweisen und
computationelle Herangehensweisen, Annotationen, Machine-Learning-Ansätze, Modellierung,
Linked Open Data (LOD) und vieles mehr nutzen. Über die „Schnittstelle Mediävistik“ lassen
sich fachliche Heterogenität und Vielfalt der Gegenstände mit der Vielfalt der Methoden
produktiv verbinden.
Die „Schnittstelle Mediävistik“ hat in ihrer vermittelnden Funktion auch unmittelbare Auswirkun-
gen auf Aspekte der Nachhaltigkeit. Denn nur durch nachhaltig verfügbare und genormte Daten,
durch die Einhaltung von Standards und die Verwendung persistenter Identifikatoren kann eine
langfristige interdisziplinäre Forschung bzw. Nachnutzung der Daten im Wechselspiel verschie-
dener Disziplinen und Methoden ermöglicht werden.
Unter zeitgemäßer digitaler Mittelalterforschung verstehen wir außerdem auch nationale und in-
ternationale Forschungsinfrastrukturen, die von Mediävist*innen mit einem gemeinsamen Inte-
resse an einer tiefgreifenden Erschließung von Forschungsgegenständen kollaborativ gepflegt
und gestaltet werden. Dies impliziert eine Offenheit, die sich nicht nur auf die Verwendung offe-
ner Standards und die interdisziplinären Perspektiven auf heterogene Forschungsgegenstände
bezieht, sondern durch die auch eine gesamtgesellschaftliche Teilhabe am zu bewahrenden
kulturellen Erbe angestrebt wird.
Ziel des Bandes
Das Forschungsfeld des Themenhefts reicht somit von methodologischen über daten- oder ob-
jektbezogene Fragestellungen hin zu infrastrukturellen Aufgaben, die unter den Aspekten der
digitalen Nachhaltigkeit und Vernetzung vereint werden. Ziel des Bandes ist, kollaborative
Verfahren der Digital Humanities forschungsorientiert und praxisnah vorzustellen und die
hierfür angewandten Methoden und Praktiken zu evaluieren und zu diskutieren.
Das Themenheft soll in erster Linie dazu einladen, das methodische Feld in Bezug auf Verfahren
der Verknüpfung und Kontextualisierung zu erweitern. Mithilfe quantitativer und kontextualisie-
render Ansätze wird eine neue Qualität von Forschungsdaten erreicht, indem verstreute Infor-
mationen systematisch miteinander verknüpft werden, sodass komplexe Zusammenhänge
sichtbar und neue Zugänge geschaffen werden. Hier bieten digitale Verfahren auch neue Per-
spektiven für eine global ausgerichtete Mediävistik. Erst diese Art der Vernetzung befördert auf
lange Sicht einen Kulturwandel. Er zeichnet sich durch transparente, offene und nachhaltige
Wissenschaft ebenso aus wie durch kollaborative und innovative Forschung und die Übernahme
der gemeinsamen Verantwortung für den Aufbau und langfristigen Betrieb digitaler Arbeitsum-
gebungen und Forschungsinfrastrukturen. Zu diesen Herausforderungen der digitalen Mediävis-
tik will der Band einen Beitrag leisten.
Themenheft „Digitale Mediävistik“ (2019)
Durch seinen Bezug zu digitalen Forschungsthemen knüpft das Themenheft an das Heft „Digi-
tale Mediävistik und der deutschsprachige Raum“ (Band 24, Heft 1) an, wählt aber durch den
hier vorgeschlagenen methodischen Fokus einen anderen Zugang zu dem Forschungsfeld. Die-
ser ermöglicht es nicht nur, einzelne Aspekte des Heftes aus dieser Perspektive neu aufzugrei-
fen, sondern insbesondere, die Thematik um andere Aspekte zu ergänzen – und dabei das Po-
tenzial vernetzter Ressourcen interdisziplinär wie international zu denken. Darüber hinaus sind
die Entwicklungen in den Digitalen Geisteswissenschaften in den letzten fünf Jahren rasant fort-
geschritten.
Mögliche Themenvorschläge und Fragestellungen
Die „Schnittstelle Mediävistik“ bietet vielfältige Anknüpfungspunkte für interdisziplinäre natio-
nale wie internationale Themen von hoher Aktualität, die im Themenheft versammelt werden
sollen:
Zentrale Themen sind beispielsweise Normdaten, Forschungsdatenmanagement und Infra-
strukturprojekte wie vernetzte Repositorien- und Speichersysteme, besonders CLARIN/DA-
RIAH und die Nationale Forschungsdateninfrastruktur (NFDI). Dazu zählen mit Text+,
NFDI4Culture, NFDI4Memory und NDFI4Objects vier geisteswissenschaftliche Konsortien, die
sich der Bewahrung des materiellen wie immateriellen Kulturerbes widmen. Für die Mediävistik
sind sie alle relevant, was den Charakter der fachlichen Schnittstelle unterstreicht. In diesem
Kontext spielt zudem einerseits die Gemeinsame Normdatei (GND) eine bedeutende Rolle, die
Standards für die Erfassung von Informationen entwickelt und die (im deutschsprachigen Raum)
größte Normdatensammlung bereitstellt. Andererseits ergeben sich durch die Nutzung von offe-
nen und kollaborativen Wissensplattformen wie Wikidata auch für die Wissenschaft neue
Möglichkeiten.
Auch Fragen nach der Modellierung von Informationen sind von Interesse, insbesondere hin-
sichtlich spezifisch mediävistischer Herausforderungen wie unsicherer Quellenlage oder ambi-
ger Informationen. Nach wie vor gibt es keinen einheitlichen Umgang mit unscharfen Daten oder
Ambiguitäten. Des Weiteren stellen textimmanente Ambiguitäten (die gar nicht disambiguiert
werden sollen) eine Herausforderung insbesondere für die digitale Erfassung von Daten dar.
Hier kann die Mediävistik also nicht auf allgemeine Standards zurückgreifen, sondern muss
(auch) fachspezifische Lösungen hervorbringen.
Die Editionsphilologie kann ebenfalls wesentlich von den hier skizzierten Möglichkeiten profi-
tieren. Für sie stellen quantitative und kontextualisierende Verfahren ein wertvolles Werkzeug
dar, das zur weiteren Generierung von Wissen und der nachhaltigen Nutzung digitaler Editionen
führen kann. Beiträge könnten etwa durchleuchten, wie das Gebiet der mediävistischen Edition-
spraxis durch kollaborative Verfahren und digitale Arbeitsmethoden an Komplexität gewinnt oder
die Daten interdisziplinär nachgenutzt werden können (z. B. Geovisualisierung).
Ein weiterer zentraler Punkt des Themenheftes können kollaborative Tools und Systeme, kol-
lektiv praktizierte De-facto-Standards und der erkenntnisgeleitete Einsatz von Forschungsin-
frastrukturen sein. Gemeinsame Initiativen wie beispielsweise Fragmentarium, Handschriften-
portal, RI OPAC, Biblissima+, IIIF, Transkribus und eScripta sind Lösungsansätze zur Bewälti-
gung und nachhaltigen Verfügbarmachung von Daten und der projektübergreifenden Nutzbar-
keit von HTR und OCR Software. Nach wie vor fehlt es aber an Dokumentationen und der Be-
schreibung von Methodologien zur Anwendung neuer Technologien auf bestehende For-
schungsdaten. Welche Erkenntnisse, positive wie negative, konnten in den Vorhaben gewonnen
werden? Besonders interessant erscheinen uns hier auch experimentelle Ansätze in der Nach-
nutzung von Forschungsdaten aus dem Bereich der interdisziplinären Mittelalterforschung sowie
Ergebnisse aus kollaborativen Forschungsprojekten.
Ein besonderes Augenmerk legen wir auf LOD, die durch die Verknüpfung strukturierter, ein-
deutig identifizierbarer Daten nicht nur die Qualität und Erschließungstiefe von Daten optimieren,
sondern durch deren Kontextualisierung auch zu einem vertieften Verständnis führen. LOD-Ver-
fahren stellen eine vielversprechende Option dar, Ressourcen zu erschließen, weiter anzurei-
chern und somit sichtbar, verfügbar und nachnutzbar zu machen. Gleichzeitig werden sie den
FAIR-Prinzipien gerecht und spiegeln damit den Anspruch einer interdisziplinären, offenen For-
schung im Sinne von Open Science wider. Es liegt in der Natur von LOD, multimodale Verlin-
kungen herzustellen, sodass auch perspektivische, disziplinenübergreifende Kollaborationen
beleuchtet werden können. Hierzu gehören insbesondere Methoden zur Kontextualisierung, die
das Erschließen jeweils geltender Episteme – eine besondere Herausforderung für historische
Bestände – ermöglichen, um eine digitale Hermeneutik zu implementieren, von der die Qualität
der Erschließungstiefe ebenso profitiert wie das Verständnis der Rezipient*innen. Disziplinen, die sich für Beiträge zu diesem Themenheft anbieten, sind demnach beispielsweise Archäologie, Byzantinistik, Didaktik, Germanistik, Geschichte, Kunstgeschichte, Musikwissen-
schaft, Philosophie, Religionswissenschaft, Romanistik, Theologie uvm. Auch interdisziplinäre
Digital-Humanities-Vorhaben sind willkommen, etwa aus den Bereichen Citizen Science, Open
Science und Open Education sowie Vorhaben, die den „computational turn” von händischen zu
zunehmend automatisierten Verfahren reflektieren (z. B. Deep Machine Learning).
Von reinen Projektbeschreibungen ist abzusehen, das Augenmerk soll auf Kontextualisierung,
Vernetzung und Methodenreflexion im Sinne der „Schnittstelle” gelegt werden.
Wir bitten um Abstracts von etwa 300–500 Wörtern auf Deutsch oder Englisch bis zum
15.11.2023. Bitte senden Sie Ihre Vorschläge an die Herausgeberinnen: info@offenesmittelalter.org
Herausgeberinnen:
Dr. Luise Borek – Technische Universität Darmstadt, Institut für Sprach- und Literaturwissen-
schaft, Deutschland
Dr. Katharina Zeppezauer-Wachauer – Universität Salzburg, Mittelhochdeutsche Begriffsdaten-
bank (MHDBDB), Österreich
Dr. Karoline Döring – Universität Salzburg, Interdisziplinäres Zentrum für Mittelalter und Früh-
neuzeit, Österreich
Bitte beachten Sie folgenden Hinweis: Das Themenheft erscheint bei Heidelberg University
Publishing im Open Access unter der Lizenz CC-BY-SA 4.0.
Planung des weiteren Ablaufs:
● Mitte Dezember 2023: Auswahl der Beiträge und Zusage an die Autor:innen
● Mitte Juni 2024: Einsendung der Beiträge; Weitergabe der Beiträge in die Begutachtung
● vorauss.10./11. Oktober 2024, Salzburg: Heft-Workshop im Stil einer
Autor:innenkonferenz zur Diskussion der Beiträge
● Anfang November 2024: Abgabe der auf der Grundlage der Gutachten und der
Workshopdiskussion überarbeiteten Beiträge
● 28. Februar 2025: Versand der lektorierten Beiträge zur letzten Prüfung an die
Autor:innen
● April 2025: Versand der Druckfahnen an die Autor:innen
● Mai/Juni 2025: Erscheinungstermin online und im Buchhandel
Link zur PDF Datei des Calls auf den Seiten des Mediävistenverbandes: https://www.mediaevistenverband.de/wp-content/uploads/Call_Das-Mittelalter_Schnittstelle-Mediaevistik.pdf