Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 26. Januar 2026, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Bastian Politycki & Alexander Häberlin (Sammlung Schweizer Rechtsquellen (SSRQ))
Die Entwicklung nachhaltiger Forschungssoftware in den Digital Humanities ist kein rein mechanisches Unterfangen, sondern ein ständiger Aushandlungsprozess zwischen technischen Anforderungen, wissenschaftlicher Arbeit und Pflege der Codebasis. Am Beispiel der „Sammlung Schweizerischer Rechtsquellen“ (SSRQ) beleuchtet dieser Vortrag die Herausforderungen, eine komplexe, historisch gewachsene Editionsinfrastruktur technisch zukunftsfähig zu halten.
Im Zentrum steht die Adaption des professionellen Research Software Engineering (RSE) für den geisteswissenschaftlichen Alltag. Methoden wie Test-Driven Development (TDD) werden nicht nur zur Validierung von Code, sondern auch zur Qualitätssicherung historischer Daten eingesetzt, womit das notwendige „Vertrauen“ in die gedruckte und digitale Edition geschaffen wird. Gleichzeitig erfordert die langfristige Wartbarkeit ein kontinuierliches Refactoring der Codebasis.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 24. November 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Wolfgang Meier(Jinntec GmbH)
Der Vortrag stellt die neueste Version von TEI Publisher vor und demonstriert einige der wesentlichen Neuerungen. TEI Publisher 10 führt die Grundidee eines modularen Werkzeugkastens fort und implementiert sie auf einer höheren Ebene: an die Stelle einer zentralen Anwendung, die jeweils auf konkrete Editionsprojekte angepasst wird, tritt nun eine Sammlung von Profilen. Jedes Profil behandelt einen spezifischen Aspekt. Profile implementieren sowohl technische Grundlagen, wie z.B. die Unterstützung für ein bestimmtes XML-Format, Kommunikationsprotokoll oder Teile der Benutzeroberfläche, wie auch funktionale Aspekte, die auf einen bestimmten Editionstyp zugeschnitten sind, z.B. die Navigation zwischen Briefen einer Korrespondenz. Auch Webdesign und Darstellung werden durch Profile festgelegt und sind entsprechend austauschbar.
Eine digitale Editionsanwendung entsteht dann durch die Kombination unterschiedlicher Profile und deren Konfiguration. Letzere erfolgt über eine zentrale Konfigurationsdatei, zu der jedes Profil seine Parameter beiträgt und aus der die Anwendung erzeugt wird. Dies vereinfacht den Entwicklungsprozeß weiter, insbesondere für Anwender ohne Programmiererfahrung. Die Entwicklung kann darüber hinaus nun völlig iterativ erfolgen, d.h. es können jederzeit einzelne Profile hinzugefügt, verändert oder entfernt werden.
Die Aufteilung in Profile verbessert neben der Wiederverwendbarkeit insbesondere auch die Wartbarkeit der Anwendung: Updates können großteils automatisch durchgeführt werden, wenn sich einzelne Profile verändern. Bislang musste dagegen jeweils die gesamte Editionsanwendung manuell angepasst werden, um von einer neueren TEI Publisher-Version zu profitieren. Mit TEI Publisher 10 kümmert sich der zentrale Anwendungsmanager, Jinks, um die Aktualisierung aller Profile und ihrer Abhängigkeiten.
Nutzer können auch eigene Profile erstellen und in die Bibliothek von TEI Publisher integrieren. Dies macht zum einen dann Sinn, wenn bestimmte funktionale oder visuelle Aspekte automatisch auf mehrere Editionsprojekte angewandt werden sollen. So kann z.B. sichergestellt werden, dass alle Publikationen einer Institution eine einheitliche Gestaltung aufweisen und festgelegte Mindeststandards einhalten. Zum anderen können Projekte, die eine bestimmte Funktionalität benötigen, diese als generalisiertes Profil zu TEI Publisher beitragen und mit anderen Projekten teilen. Damit steigt die Wahrscheinlichkeit, dass das entsprechende Profil auch auf längere Sicht verfügbar bleibt und gewartet wird.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Marcus Lampert aus der TELOTA-Abteilung der BBAW stellt ein neues ediarum-Modul vor: ediarum.WEBDAV. Vor einem Jahr an der BBAW eingeführt, verfolgt ediarum.WEBDAV das Ziel, ein sicheres und transparentes System für das Bearbeiten, Speichern und Sichern von XML-Forschungsdaten bereitzustellen. Mittlerweile nutzen bereits fast zehn Projekte an der BBAW die Software täglich.
Marcus wird die Software aus verschiedenen Blickwinkeln vorstellen: Zunächst demonstriert er, wie Nutzerinnen und Nutzer über Oxygen und die Benutzeroberfläche mit dem System arbeiten. Anschließend zeigt er, wie ediarum.WEBDAV automatische Git-Commits verwendet, um XML-Forschungsdaten zuverlässig zu speichern und zu sichern. Schließlich werden wir gemeinsam einen Blick auf Teile des Codes werfen, um zu verstehen, wie das Laravel-Framework die verschiedenen Komponenten der Software koordiniert.
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/nad-mge-0rq-ufp erreichbar.
Das ediarum.MEETUP ist primär für DH-Entwickler:innen gedacht, die sich zu spezifischen ediarum-Entwicklungsfragen austauschen wollen, jedoch sind auch ediarum-Nutzer:innen und Interessierte herzlich willkommen.
Wir freuen uns auf zahlreiches Erscheinen!
Viele Grüße Nadine Arndt im Namen der ediarum-Koordination
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 27. Oktober 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Tim Westphal (BBAW, TELOTA), Marco Santi (BBAW), Mario Tormo Romero(Hasso-Plattner-Institut, Potsdam)
Seit Beginn der Arbeit an einer historisch-kritischen Edition Gottfried Wilhelm Leibniz im Jahr 1901 bildet die Datierung des umfangreichen handschriftlichen Nachlasses eine große editorische Hürde. Rund 100.000 Blätter aus der Hand des letzten Universalgelehrten dokumentieren eine über fünf Jahrzehnte reichende intellektuelle Entwicklung, wobei einem Großteil der Schriftstücke eine zeitgenössische Datierung fehlt. Traditionelle Methoden der Datierung sind für einen Korpus dieser Dimension unzureichend: Die manuelle Bestimmung durch Expertinnen ist angesichts der Materialmenge praktisch nicht zu bewältigen, und auch die Wasserzeichenanalyse erlaubt nur grobe Annäherungen im Bereich von Jahrzehnten.
Der Beitrag erprobt, inwieweit bildgestützte Deep-Learning-Modelle diese Lücke schließen können und ob diese dabei eine editorisch nutzbare Genauigkeit erreichen. Wünschenswert ist eine maximale Abweichung von ±1 Jahr. Im Mittelpunkt steht die Frage, ob Deep-Learning-Modelle die feinen intra-personalen Schreibdrifts eines einzelnen Autors über fast fünf Jahrzehnte abbilden können. Anders als bestehende Arbeiten, die meist das Alter verschiedener Schreiber klassifizieren, zielt der Ansatz auf die Detektion des schreibereigenen Stilwandels innerhalb Leibniz‘ Werk. Der weitläufige Nachlass von Leibniz bietet hierfür eine geeignete Grundlage.
Es wird bewusst auf Transkription oder OCR verzichtet, so werden die besonderen Herausforderungen von Leibniz‘ Schriftbild (Überarbeitungen, Streichungen, wechselnde Sprachen) umgangen. Um sicherzustellen, dass die Modelle schriftbezogene und nicht materialbedingte Merkmale lernen, werden verschiedene Normalisierungsschritte durchgeführt: Zeilenweise Segmentierung und Binarisierung eliminieren Papierstruktur und Tintenintensität als Faktoren.
Als Datenbasis dienen ca. 600 Seiten aus dem Zeitraum 1669-1716: 400 datierte Briefe sowie 200 Seiten wissenschaftlicher Ausarbeitungen. Das Material wurde so gewählt, dass für jedes Jahr Vorlagen verfügbar sind. Es werden verschiedene Deep-Learning-Architekturen entwickelt und evaluiert, die relevante Merkmale direkt aus den Bilddaten lernen. Anders als klassische Ansätze der digitalen Paläographie mit manueller Merkmalsextraktion wird auf ein Ende-zu-Ende-Lernverfahren gesetzt. Ziel des Projekts ist die Entwicklung von Ansätzen zur hochauflösenden Datierung frühneuzeitlicher Gelehrtenhandschriften für den Einsatz in der alltäglichen editorischen Praxis. Die entwickelte modulare Pipeline ermöglicht flexibel konfigurierbare Experimente und legt besonderen Wert auf Visualisierung und Erklärbarkeit der Ergebnisse.
Das Projekt positioniert sich an der Schnittstelle von Digital Humanities und Computer Vision und zeigt, wie klassisches maschinelles Lernen die traditionelle editorische Arbeit ergänzen kann. Es entsteht in Kooperation zwischen der Leibniz-Arbeitsstelle der BBAW, dem DH-Referat TELOTA und dem KI-Servicezentrum des Hasso-Plattner-Instituts in Potsdam.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Bei TELOTA an der Berlin-Brandenburgischen Akademie der Wissenschaften ist derzeit eine Stelle im Bereich Digital Humanities und Forschungssoftwareentwicklung für Digitale Editionen im Umfang von 100 % der regelmäßigen wöchentlichen Arbeitszeit ausgeschrieben. Die Stelle ist vorerst befristet auf 24 Monate (ggf. teilbar). Bewerbungsfrist ist der 21.10.2025.
Entwurf, Entwicklung und Anpassung von zentralen, digitalen Forschungswerkzeugen und -umgebungen der BBAW
Entwurf und Entwicklung von Daten- und Programmierschnittstellen (APIs) zur Visualisierung und Vernetzung von Forschungsdaten
Weiterentwicklung digitaler Methoden unter Einsatz aktueller Technologien wie Machine Learning oder Knowledge Graphs
Dokumentation der Entwicklungsarbeiten
Mitarbeit bei der Antragstellung und Berichterstattung von Projektanträgen im Rahmen von regionalen, nationalen und internationalen Forschungsförderungen
Präsentation der Arbeits- und Forschungsergebnisse auf einschlägigen Konferenzen und Workshops
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 29. September 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Fernanda Alvares Freire (BBAW, TELOTA)
This presentation explores how Social Network Analysis (SNA) can be applied to study social interactions as represented in historical letter corpora. By combining qualitative text analysis with Social Network Analysis (SNA), the approach models and visualizes interpersonal relations to investigate patterns of interaction, the roles of key actors, and the structure of historical communities. As one of the largest collections from the Hellenistic period, the letters and documents of the Zenon archive provide rich information about administrative, economic, and personal networks and serve as an exemplary use case to the approach. Applying SNA to this corpus highlights the potential and challenges of working with large corpora of written communication and serves as an example of how this framework can be extended to other epistolary datasets.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 14. Juli 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Fabian Moss (Julius-Maximilians-Universität Würzburg) über Text+ Musik: Multimodale Kodierungsherausforderungen im DigiMusTh-Kooperationsprojekt
***
Das Text+-Kooperationsproject »DigiMusTh« hat den Aufbau einer offenen digitalen Sammlung historischer musiktheoretischer Texte aus dem deutschsprachigen Raum anhand von Beispielen aus dem 19. Jahrhundert zum Ziel. Diesem Unterfangen stehen eine Reihe besonderer Herausforderungen gegenüber, die sich vornehmlich aus der Multimodalität der Dokumente ergeben, welche neben Text auch Bilder, Grafiken, sowie Musiknotation enthalten. Der Beitrag präsentiert den aktuellen Stand des Projekts, erläutert einige dieser Herausforderungen und stellt Lösungsvorschläge zur Debatte.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Zum Thema Encoding Gender kündigen wir folgende Beiträge an:
Themenblock Kodierung
Nadine Arndt (BBAW/TELOTA): Auszeichnung von „sex“ & „gender“ in ediarum
Marius Hug und Frank Wiegand (BBAW/Text+): Bevorzugte Waffen der Frauen – Annotationen im Deutschen Textarchiv als Voraussetzung für eine genderspezifische Korpusanalyse mit dem DWDS
Themenblock Normdaten
Sabine von Mering (Museum für Naturkunde Berlin): Das Potenzial von Wikidata für die Sichtbarmachung von Frauen – Gender data gap in der Naturkunde
Julian Jarosch, Denise Jurst-Görlach und Thomas Kollatz (Akademie der Wissenschaften und der Literatur Mainz): Genderattribution in der GND und entityXML am Beispiel der Korrespondenz Martin Bubers
Das Meetup soll den Austausch fördern, Problemfelder identifizieren und gemeinsam Lösungsansätze erarbeiten. Wir freuen uns auf vielseitige Perspektiven und eine lebhafte Diskussion!
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/nad-mge-0rq-ufp erreichbar.
Das ediarum.MEETUP ist primär für DH-Entwickler:innen gedacht, die sich zu spezifischen ediarum-Entwicklungsfragen austauschen wollen, jedoch sind auch ediarum-Nutzer:innen und Interessierte herzlich willkommen.
Wir freuen uns auf zahlreiches Erscheinen!
Viele Grüße Nadine Arndt und Frederike Neuber im Namen der ediarum-Koordination und der Gender & Data-Arbeitsgruppe
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 26. Mai 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Philipp Bayerschmidt und Cord Pagenstecher über Oral-History.Digital – Der Aufbau eines Interviewportals und die Erschließung heterogener Archive mit Topic Modeling
***
Das Interviewportal „Oral-History.Digital“ ist eine von der Freien Universität Berlin betriebene Erschließungs- und Recherche-Plattform für wissenschaftliche Sammlungen von audiovisuellen Forschungsdaten (www.oral-history.digital). Universitäten, Museen und Stiftungen können ihre Audio- und Video-Interviews hochladen, mit Werkzeugen für Transkription oder Verschlagwortung bearbeiten und mit einem granularen Rechtemanagement für Bildung und Wissenschaft bereitstellen. Interessierte können die inzwischen über 4000 Interviews von rund 40 Institutionen sammlungsübergreifend durchsuchen. Angemeldete Nutzende können die Aufnahmen mit Untertiteln ansehen, annotieren und zitieren.
Zur Unterstützung der teilnehmenden Interviewarchive hat die an „Oral-History.Digital“ mitwirkende FernUniversität Hagen einen Topic-Modeling-Service entwickelt, der die automatische Erstellung von Inhaltsverzeichnissen und Themenregistern unterstützt. Grundlage ist ein auf Basis von 991 Interviews aus sieben verschiedenen Archiven berechnetes und evaluiertes Topic-Modell. Über ein Register von 100 Topics können nun gezielt Textpassagen zu entsprechend gelabelten Themen gefunden werden. Der Orientierung innerhalb der mehrstündigen Interviews dienen klickbare Inhaltsverzeichnisse, die aus den Topics erzeugt wurden. Zudem unterstützt ein interaktives Dashboard die Analyse der Interviews.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Im Namen des Konsortiums Text+ der Nationalen Forschungsdateninfrastruktur (NFDI) und des ediarum-Teams an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) sowie in Kooperation mit der Gender & Data-Arbeitsgruppe der BBAW freuen wir uns, das nächste virtuelle ediarum.Meetup anzukündigen:
Neben einer Einführung in die Thematik und einer Vorstellung der ediarum-Funktion zur Kodierung von Sex und Gender laden wir Projekte, die sich mit der Kodierung von Gender beschäftigen, ein, kurze Beiträge (ca. 5–10 Minuten) einzureichen. Das Meetup soll den Austausch zu diesem Thema fördern, Problemfelder identifizieren und gemeinsam Lösungsansätze erarbeiten. Ob Herausforderungen bei der Modellierung oder konkrete Lösungsansätze in TEI/XML – wir freuen uns auf vielseitige Perspektiven und eine lebhafte Diskussion!
Wenn Sie einen 5- bis 10-minütigen Impulsbeitrag zum Thema „Encoding Gender“ leisten möchten, senden Sie bitte eine kurze, informelle Beschreibung Ihres Beitrags bis zum 15. Mai 2025 an neuber@bbaw.de.
Viele Grüße,
Nadine Arndt und Frederike Neuber im Namen der ediarum-Koordination und der Gender & Data-Arbeitsgruppe
* Aus organisatorischen Gründen weichen wir diesmal leicht vom angestammten Rhythmus ab.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 24. Februar 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Hannes Bajohr (University of California, Berkeley) über Distanzierte Autorschaft
***
Der Vortrag gibt einen Überblick über den Begriff der Autorschaft in KI und in Systemen zur Verarbeitung natürlicher Sprache und erörtert frühere und aktuelle Debatten über Computer als literarische Autoren. Er schlägt das Konzept der kausalen Autorenschaft vor, um die Arten der Distanz zwischen menschlichen und maschinellen Agenten zu messen, wobei er die anthropozentrische Ausrichtung dieser Idee anerkennt. Als Gegengewicht dazu wird der Begriff der verteilten Autorschaft diskutiert, der das Netzwerk der an der Entstehung eines Textes beteiligten Akteure berücksichtigt und seine eigenen Grenzen hat. Beide Konzepte sind Elemente einer zukünftigen Theorie der Autorschaft im Zeitalter des maschinellen Lernens.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich ein zum ersten Termin im neuen Jahr am Montag, den 27. Januar 2025, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Simone Franz über Wissen im Netzwerk. Praxisrelevante Ansätze zur Überführung von Forschungsdaten digitaler Editionen in Knowledge-Graphen
***
Der Vortrag beleuchtet das Zusammenspiel digitaler Editionen, Knowledge-Graphen und bibliothekarischer Wissensorganisation. Dabei nehmen Terminologien wie kontrollierte Vokabulare, Normdaten und Ontologien als vermittelnde Elemente für die disziplinübergreifende semantische Vernetzung von Forschungsdaten und die Wissenskodierung eine zentrale Rolle ein.
Ausgehend von einer Kombination semi-strukturierter Leitfadeninterviews sowie einer Datenmodellierung stellt der Vortrag ausgewählte empirische Befunde zur Analyse des Potentials von Knowledge-Graphen für digitale Editionen vor. Vor dem Hintergrund des Aufbaus von Knowledge-Graphen in den geistes- und kulturwissenschaftlichen Konsortien der Nationalen Forschungsdateninfrastruktur (NFDI) geht er der Frage nach, wie Forschungsdaten digitaler Editionen (bspw. XML/TEI-Registerdateien) semantisch angereichert, geöffnet und nachnutzbar gemacht werden können, um sie in Knowledge-Graphen zu überführen. Dabei werden unter anderem Gender Biases in Wissensbasen, Datenqualität und -herkunft sowie die Bedeutung wissenschaftlicher Bibliotheken und Informationsinfrastrukturen diskutiert.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Die Berlin-Brandenburgische Akademie der Wissenschaften sucht für die Mitarbeit im Akademienvorhaben KIŠIB sowie für ihr Referat TELOTA zur Mitarbeit in weiteren Vorhaben der bild- und objektbasierten Forschung zum frühestmöglichen Zeitpunkt eine/einen wissenschaftliche/n Mitarbeiter/in (m/w/d) im Bereich Informatik und Archäoinformatik / Digital Cultural Heritage / Digital Humanities im Umfang von 100% der vollen tariflichen Arbeitszeit, vorerst befristet auf 24 Monate, ggf. teilbar.
Das Referat TELOTA an der Berlin-Brandenburgische Akademie der Wissenschaften sucht eine*nwissenschaftliche*n Mitarbeiter*in im Bereich digitale Editionen, Schwerpunkt Briefeditionen und Entwicklung und Analyse mit X-Technologien und Python. Die Vollzeitstelle ist auf 24 Monate befristet und nach E13 TV-L Berlin vergütet.
Die BBAW bietet ein attraktives Arbeitsumfeld in Berlin-Mitte mit familienfreundlichen Arbeitsbedingungen. Zu den Zusatzleistungen gehören 30 Urlaubstage, betriebliche Altersvorsorge, vermögenswirksame Leistungen und ein VBB-Firmenticket-Zuschuss. Die Position ermöglicht die wissenschaftliche Weiterentwicklung in einem aktiven Digital-Humanities-Umfeld und die Mitarbeit in einem engagierten Team.
im Namen des Konsortiums Text+ der Nationalen Forschungsdateninfrastruktur (NFDI) und des ediarum-Teams an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) laden wir Sie herzlich zum nächsten virtuellen ediarum.MEETUP ein:
am Montag, dem 25. November 2024, 11:00 Uhr s.t.
Dieses Mal wollen wir ohne projektspezifischen Input mit Ihnen ins Gespräch kommen und erfahren, woran Sie derzeit im ediarum-Kontext arbeiten.
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/nad-mge-0rq-ufp erreichbar.
Das ediarum.MEETUP ist primär für DH-Entwickler:innen gedacht, die sich zu spezifischen ediarum-Entwicklungsfragen austauschen wollen, jedoch sind auch ediarum-Nutzer:innen und Interessierte herzlich willkommen.
Wir freuen uns auf zahlreiches Erscheinen! Viele Grüße Nadine Arndt im Namen der ediarum-Koordination
Seit 2014 sammelt correspSearch die Metadaten von edierten Briefen und stellt sie zur projektübergreifenden Recherche bereit. Pünktlich zum runden Geburtstag gibt es jetzt neue Features: Visualisierungen, Volltextsuche und einen SPARQL-Endpoint. Über 270.000 edierte Briefe sind recherchierbar. Grund genug, nicht nur die neuen Funktionen vorzustellen, sondern auch zurück zu blicken und zu schauen, was noch kommt.
Von Stefan Dumont, Sascha Grabsch, Jonas Müller-Laackman, Ruth Sander und Steven Sobkowski
Blick zurück
Vor zehn Jahren, genauer gesagt am 1. September 2014, ging correspSearch mit einer E-Mail an die TEI-Liste und einem DHd-Blogpost offiziell online. Die Initiative zum Webservice war im Februar 2014 im Workshop „Briefeditionen um 1800: Schnittstellen finden und vernetzen“ entstanden, der von Anne Baillot und Markus Schnöpf an der BBAW organisiert worden war. Dort stellte Peter Stadler die Überlegungen zum geplanten TEI-Element correspDesc vor und äußerte in diesem Rahmen auch die Idee, über ein Austauschformat Korrespondenzmetadaten aus Briefeditionen bereitzustellen und editionsübergreifend zu aggregieren (Stadler 2014).
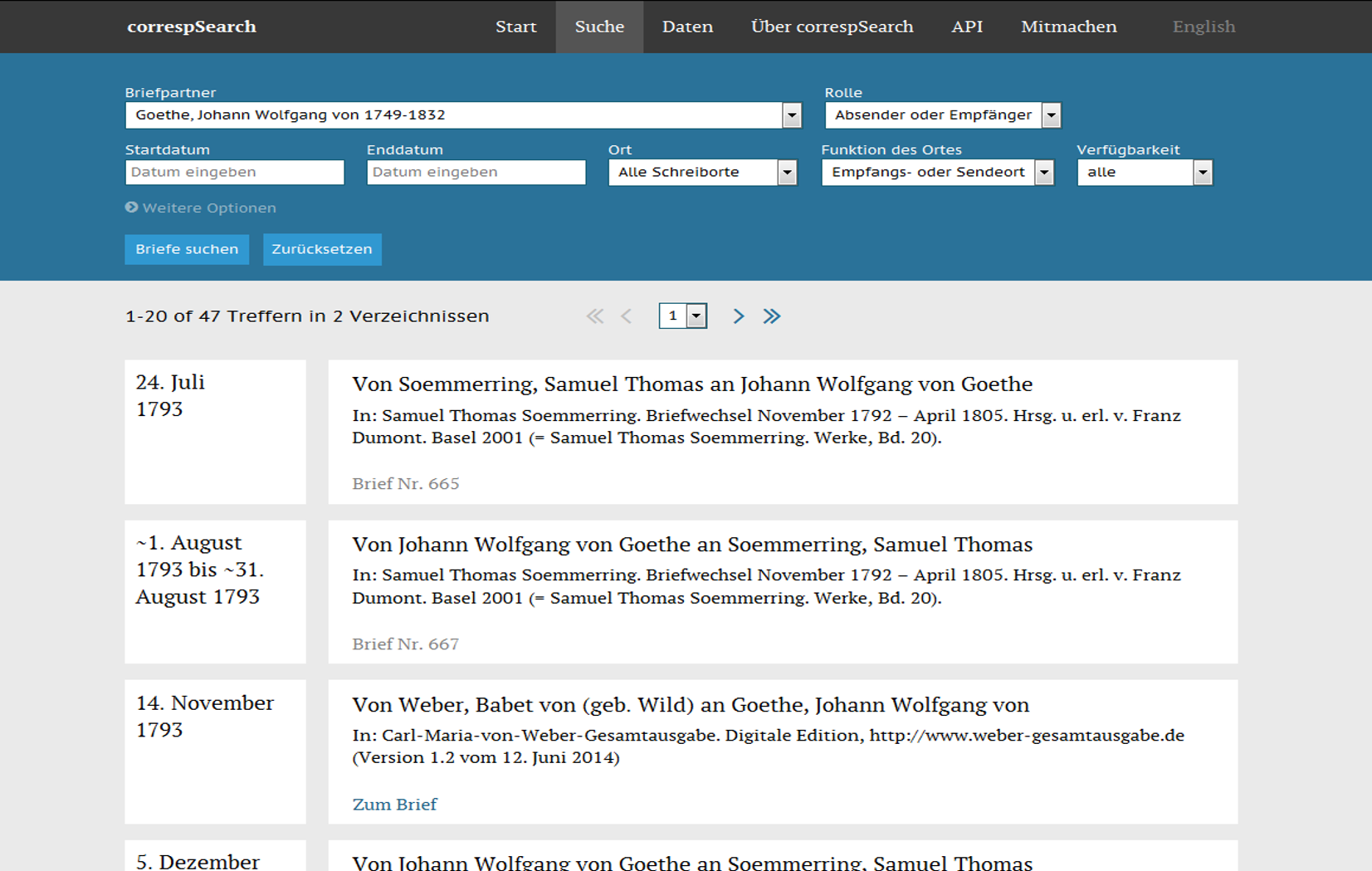
Screenshot der Suchoberfläche im Prototypen von correspSearch, ca. 2015
Im Nachgang zum Workshop wurde an der BBAW von Stefan Dumont der Prototyp eines Webservices entwickelt, der Dateien aggregieren und basal schon recherchierbar machen konnte: correspSearch (Dumont 2018; 2023). Gleichzeitig wurde von einer Taskforce der TEI Correspondence SIG die Modellierung von correspDesc abgeschlossen (Stadler, Illetschko und Seifert 2016). Mit dem Eingang von correspDesc in die TEI-Richtlinien (Version 2.8.0) im Frühjahr 2015 konnte auch das Correspondence Metadata Interchange Format (CMIF), das ebenfalls im Rahmen der TEI Correspondence SIG entwickelt wurde, in einer ersten Version finalisiert werden. Das CMIF setzt auf ein sehr reduziertes und restriktives Set an Elementen (und damit Informationen). Charakteristisch ist die konsequente Nutzung von URIs aus Normdateien wie der Gemeinsamen Normdatei (GND) für Personen und GeoNames für Orte. Dadurch können diese Entitäten projektübergreifend eindeutig identifiziert und gesucht werden.
Von Beginn an war correspSearch auf die Datenbereitstellung seitens der Editionsvorhaben, Forschungsprojekte und Institutionen angewiesen. Datenbeiträger der ersten Stunde waren z.B. die Weber-Gesamtausgabe und Briefe und Texte aus dem intellektuellen Berlin um 1800. In den folgenden Jahren wuchs der Datenbestand langsam, aber stetig an. Im Sommer 2016 konnten schon über 17.000 edierte Briefe nachgewiesen werden. Das – und die Auszeichnung von correspSearch mit dem Berliner DH-Preis 2015 – gab Rückenwind für die Beantragung eines DFG-Projekts. Der Antrag wurde dankenswerterweise positiv beschieden und das Projekt konnte 2017 starten.
Im Rahmen des DFG-Projekts wurde der Prototyp durch eine neue, modularisierte Softwarearchitektur ersetzt, die im Kern vor allem auf die Suchmaschinensoftware Elasticsearch setzt. Dadurch können auch sehr große Mengen an Meta- und Volltext-Daten (zu letzterem siehe weiter unten) performant durchsucht werden. Auch für Harvesting, Ingest und API wurden jeweils neue Applikationen entwickelt, die einen sicheren und stabilen Produktivbetrieb gewährleisten.
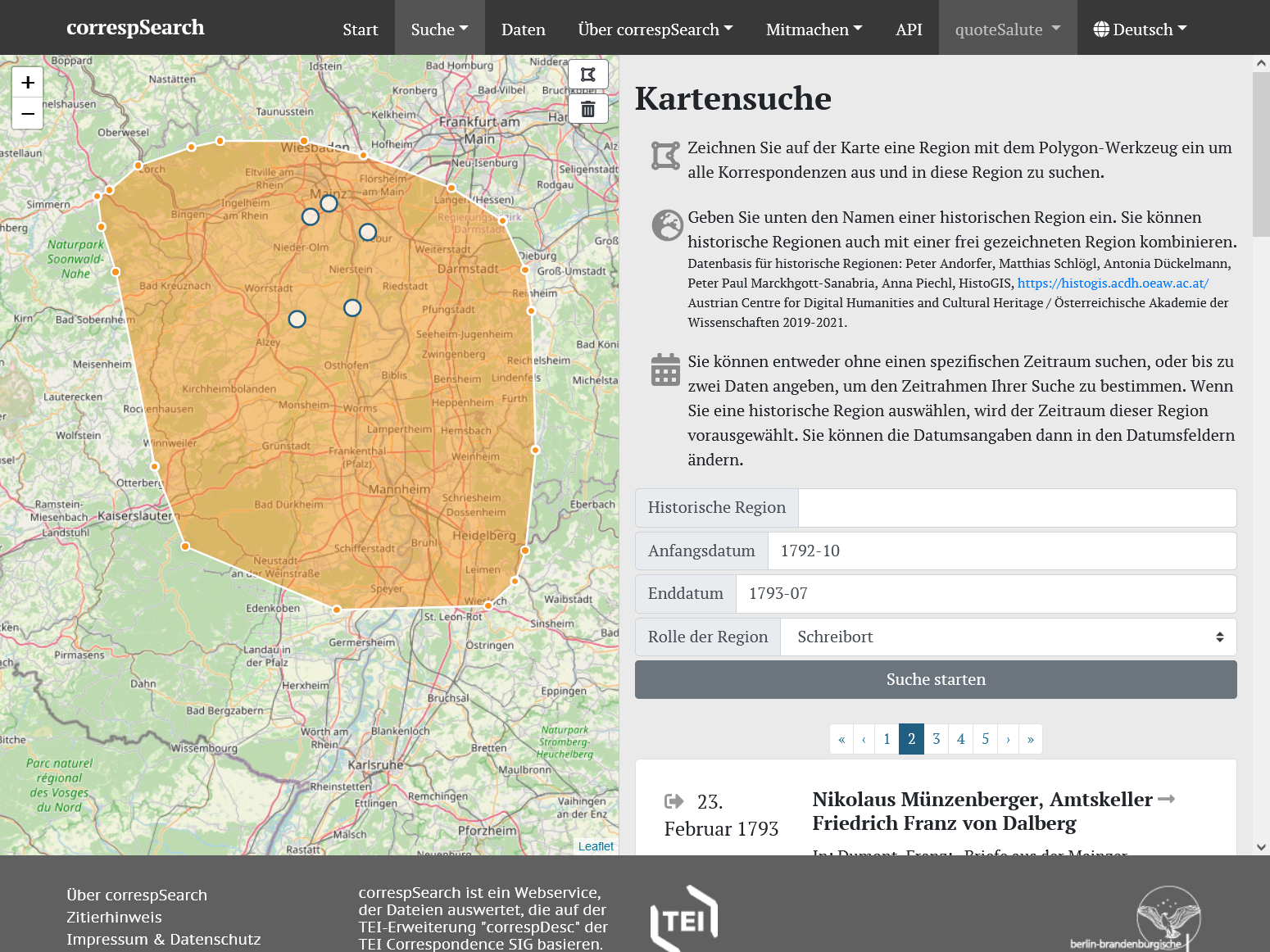
Kartenbasierte Suche in correspSearch
Die Software Elasticsearch ermöglichte auch eine facettierte Suche, so dass Suchergebnisse weiter exploriert und gefiltert werden können. Dabei wurden auch einige Filter entwickelt, die erst durch die Anreicherung der aggregierten CMIF-Daten mit weiteren Normdaten möglich werden. So können jetzt auch Briefe nach Geschlecht sowie Berufen ihrer Korrespondenten:innen recherchiert werden. Dazu nutzt correspSearch Daten aus der Gemeinsamen Normdatei und Wikidata nach. Mit Hilfe der von GeoNames bezogenen Geokoordinaten kann z.B. die kartenbasierte Suche benutzt werden. Hier kann nach Briefen anhand einer Region gesucht werden, die entweder frei eingezeichnet wird oder aus einem in HistoGIS vorgehaltenen, historischem Staatsgebiet (nach 1815) ausgewählt wird. Die neue Suchoberfläche wurde in Vue.js umgesetzt, die Website insgesamt ist nun responsiv und kann daher auf allen Endgeräten genutzt werden.
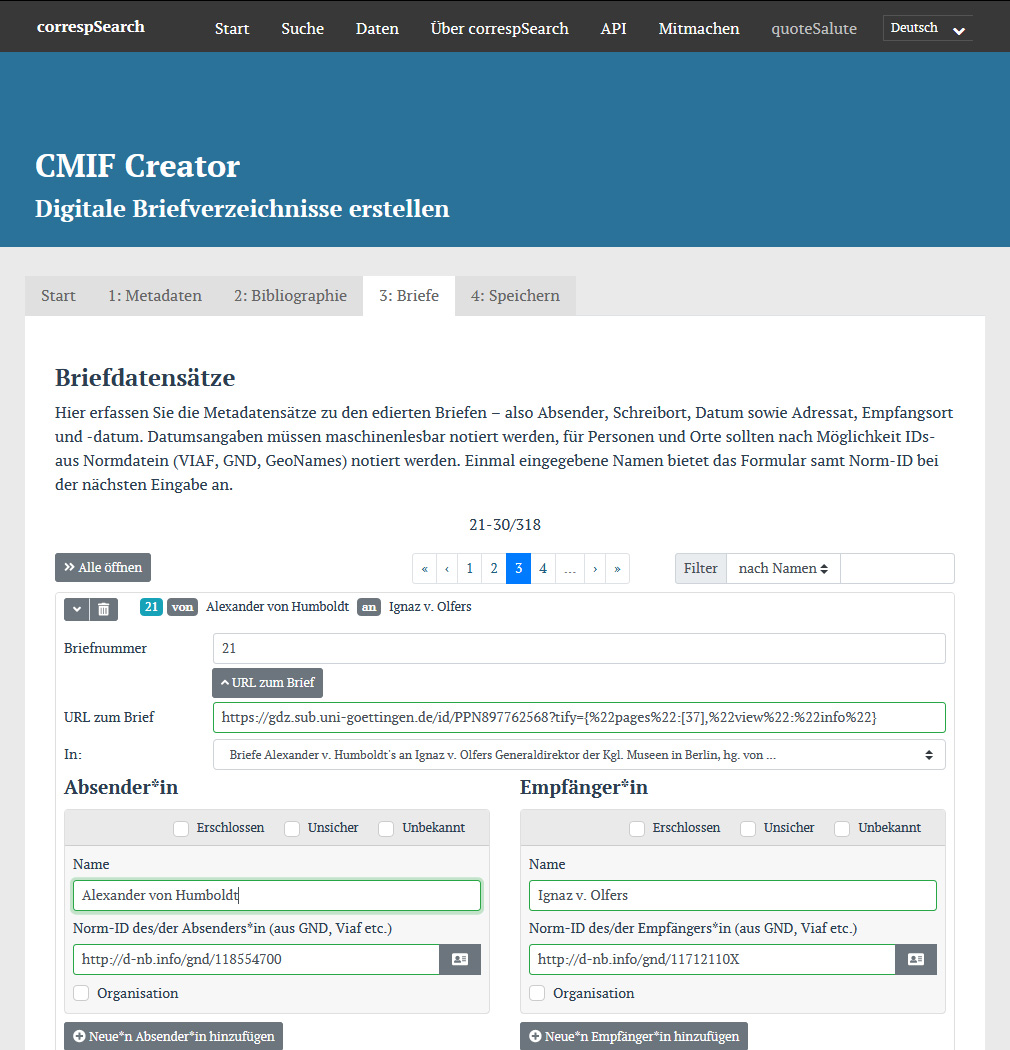
Erfassungsmaske im CMIF Creator
Darüber hinaus wurde mit dem CMIF Creator ein browserbasiertes Eingabeformular geschaffen, mit dessen Hilfe Wissenschafter:innen ohne technische Vorkenntnisse digitale Briefverzeichnisse ihrer Editionen erstellen können. Bei der Eingabe von Personen und Orten kann auch direkt bequem die GND bzw. GeoNames angefragt werden, um Normdaten-IDs für Personen und Orte zu ergänzen. Die Services CMIF Check und CMIF Preview unterstützen die Überprüfung von CMIF-Dateien. Außerdem wurden eigens Erklärvideos zu correspSearch und zum CMIF Creator produziert, die die bereits vorhandene Dokumentation ergänzen. Auch die Community stellte dankenswerterweise Tools für die CMIF-Erstellung bereit: So entwickelte Klaus Rettinghaus das Python-Tool CSV2CMI, das CSV-Tabellen in CMIF-Dateien umwandeln kann. Das Tool wird von der Sächsischen Akademie der Wissenschaften auch als Webservice angeboten – ergänzt um den Dienst ba[sic]?. Julian Jarosch (Akademie der Wissenschaften und der Literatur Mainz) entwickelte vor kurzem die eXistdb-Funktionsbibliothek CMIFerator, mit deren Hilfe eine CMIF API in eXistdb umgesetzt werden kann.
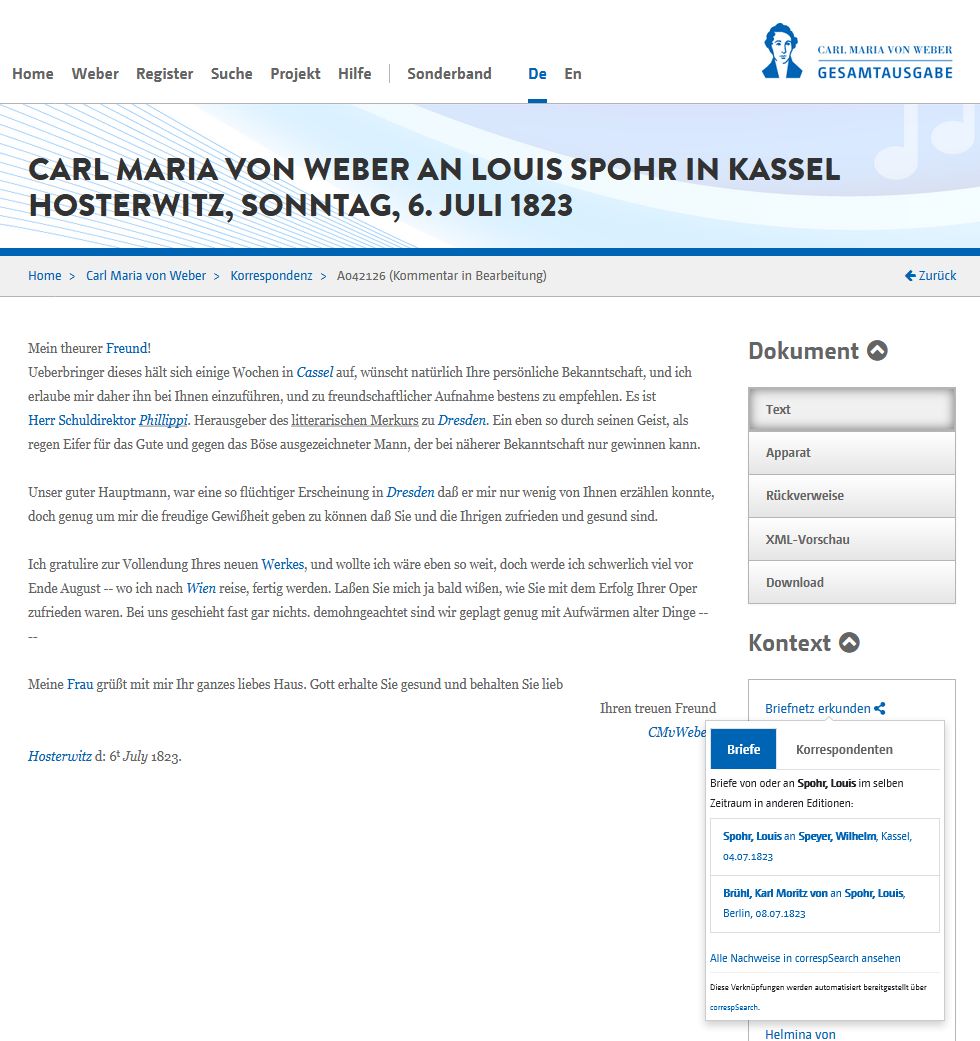
Das Widget csLink im Einsatz in der Weber-Gesamtausgabe (unten rechts)
Im DFG-Projekt wurde außerdem das Javascript-Widget csLink entwickelt, das zu einem edierten Brief in der eigenen digitalen Edition auf zeitlich benachbarte Briefe der Korrespondenzpartner:innen aus anderen Editionen hinweist (dafür fragt es die API von correspSearch ab). Dieser ‚erweiterte Korrespondenzkontext‘ kann sehr interessant sein, denn eine Person kann über ein Ereignis etc. an verschiedene Korrespondenzpartner schreiben – und das unter Umständen auch mit unterschiedlichem Inhalt (Dumont 2023, 745). Das Widget csLink ist unter einer freien Lizenz publiziert und kann von jeder digitalen Edition nachgenutzt werden.
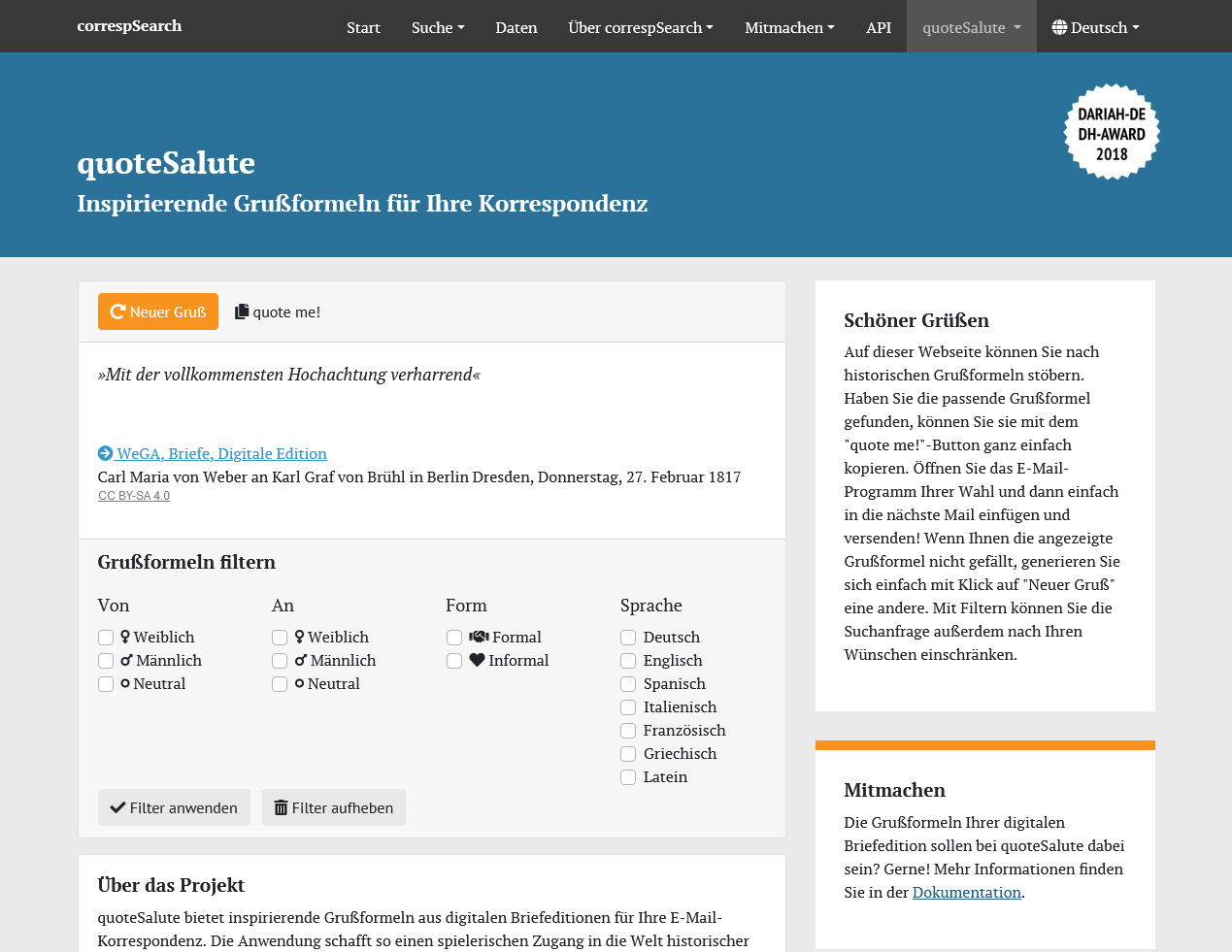
2018 kam ein kleines Nebenprojekt hinzu, das von Student:innen initiiert und umgesetzt wurde: quoteSalute (Lou Klappenbach, Marvin Kullick und Louisa Philipp, betreut von Stefan Dumont, Frederike Neuber und Oliver Pohl). Der Dienst quoteSalute bietet kuratierte Grußformeln aus edierten Briefen an, die in der eigenen (E-Mail-)Korrespondenz verwendet werden können (siehe hierzu auch den Artikel im DHd-Blog). QuoteSalute wurde mit dem DARIAH-DE DH-Award 2018 ausgezeichnet. Im selben Jahr wurde zudem der community-getriebene Projektverbund aus correspDesc, CMIF & correspSearch mit dem Rahtz Price for TEI Ingenuity der Text Encoding Initiative ausgezeichnet.
CorrespSearch ist für die aggregierten Daten übrigens keine Einbahnstraße: Der Webservice kann auch – übrigens bereits seit dem Launch 2014 – über APIs abgefragt und die Daten unter einer freien Lizenz maschinenlesbar abgerufen werden. Als Formate stehen TEI-XML, TEI-JSON sowie CSV zur Verfügung – in der API-Dokumentation können die Details eingesehen werden. Im Herbst 2023 wurde die technisch rundum erneuerte API 2.0 gelauncht, die auch bei großen Abfragen eine gute Performance gewährleistet. Darüber hinaus bietet eine BEACON-Schnittstelle die Möglichkeit, die in correspSearch nachgewiesenen Korrespondenzen automatisiert (etwa aus Personenregistereinträgen) zu verknüpfen. Und dank Klaus Rettinghaus steht auch in der (deutsch- und englischsprachigen) Wikipedia eine Vorlage bereit, um anhand der GND-ID von Wikipediaartikeln zu Personen aus zu deren Korrespondenzen in correspSearch zu verlinken.
Stand der Dinge: Version 3.0 mit Visualisierungen und Volltextsuche
Vor kurzem konnte das DFG-Projekt erfolgreich abgeschlossen werden und die Version 3.0 des Webservices correspSearch freigeschaltet werden. Damit einhergehend stehen nun auch neue Funktionen bereit. Neben Verbesserungen wie durchsuchbare Facetten, wurden auch zwei grundlegend neue Funktionen eingeführt.
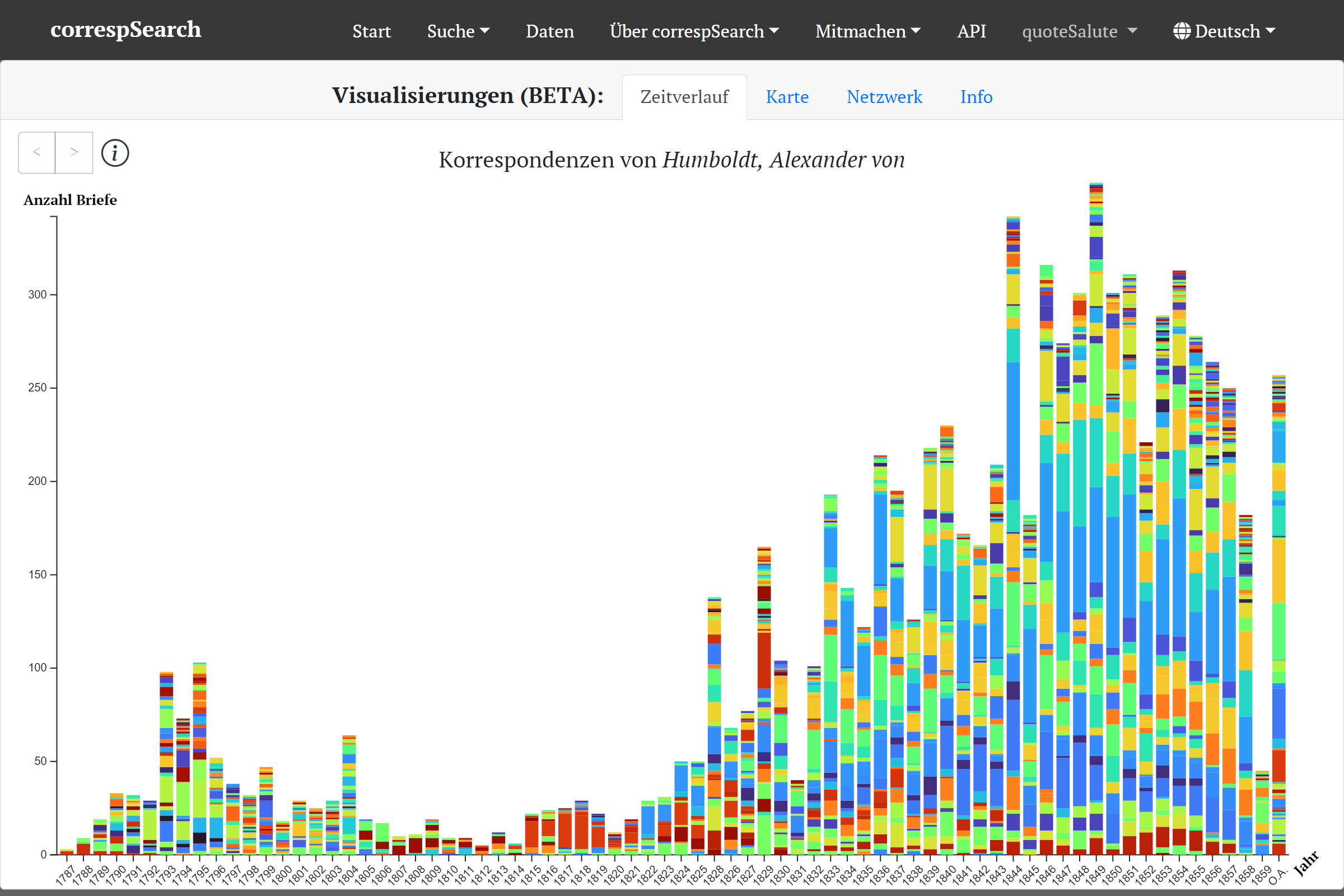
Die (publizierte) Korrespondenz von A. v. Humboldt im Zeitverlauf visualisiert
Zum einen können Suchergebnisse nun auch in Visualisierungen exploriert werden. Zur Auswahl stehen drei verschiedene Visualisierungstypen: Zeitverlauf (als gestapeltes Balkendiagramm) der Korrespondenzen, Kartenansicht der Schreib- und Empfangsorte (ebenfalls im Zeitverlauf) und Netzwerkdarstellung der Korrespondenzpartner:innen. Alle drei Visualisierungen können aus dem Suchergebnis heraus (also nach dem Ausführen einer initialen Suche) aufgerufen werden. Je nach Suche eignen sich die verschiedenen Visualisierung unterschiedlich gut für eine weitere Exploration. Während der Zeitverlauf gut für die Darstellung einer Gesamtkorrespondenz ist (etwa die von Constance de Salm-Salm), eignet sich die Kartenansicht besonders gut für Reisekorrespondenzen (etwa die von A. v. Humboldt 1829 in Russland).
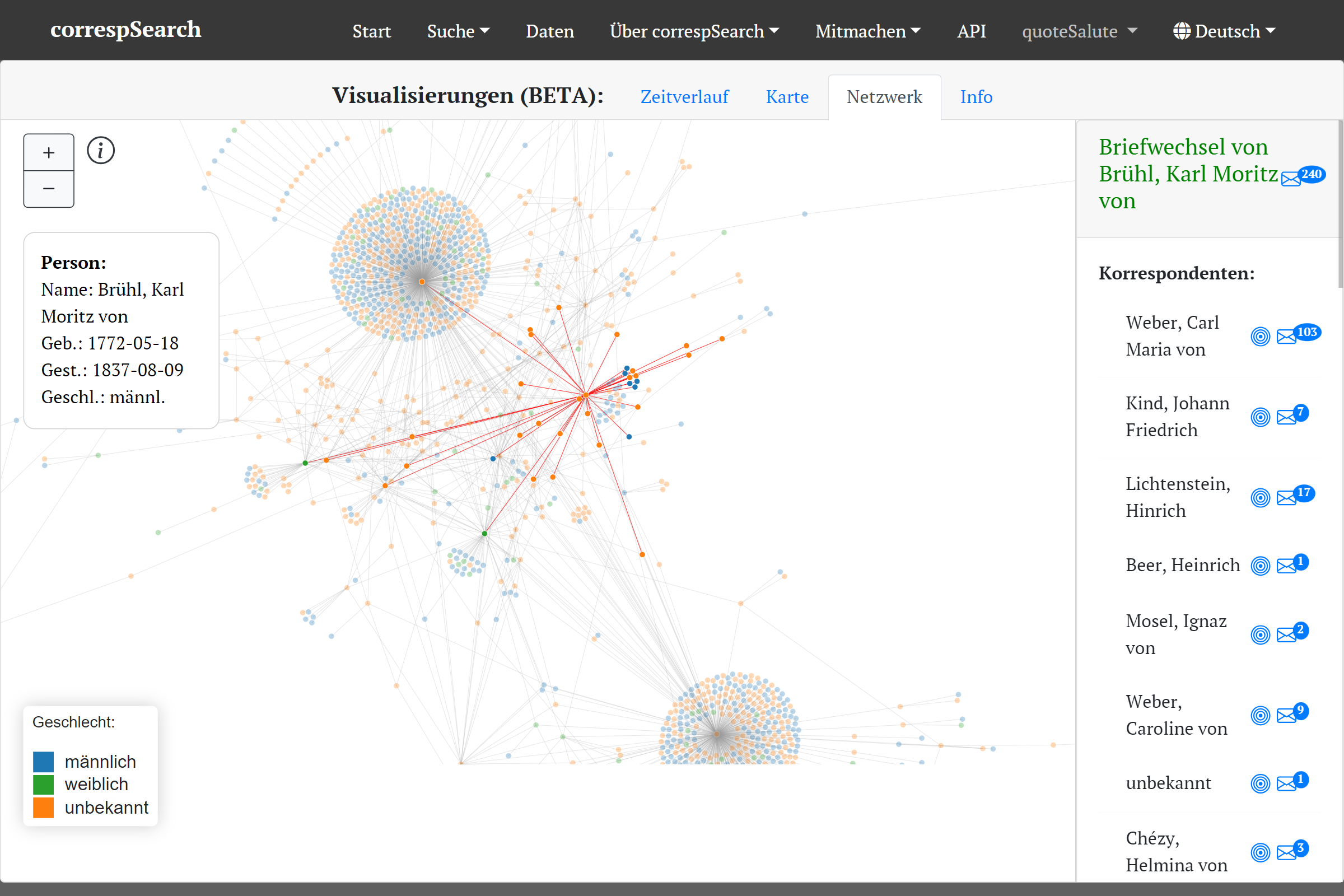
Korrespondenznetz aus den Daten der Weber-Gesamtausgabe
Die Netzwerkansicht dagegen ist interessant für nicht personenzentrierte Abfragen oder Editionen, die auch Briefe Dritter bzw. aus dem Umfeld enthalten (z.B. der Weber-Gesamtausgabe). Außerdem lassen sich mit ihr auch gut Briefnetze und Briefnetzwerke von ganzen Zeitschnitten erkunden (etwa 1789-1798). Allen Visualisierungen kann man durch Zoom-Funktion und Pop-Ups die zugrundeliegenden Metadaten entnehmen. Auch ist ein Wechsel zurück ins Suchergebnis für detailliertere Recherchen an vielen Stellen möglich. Das reibungslose “Switchen” vom Suchergebnis in die Visualisierung und zurück war ein zentraler Punkt im Konzept der Visualisierungen, die mit Hilfe von D3.js umgesetzt wurden.
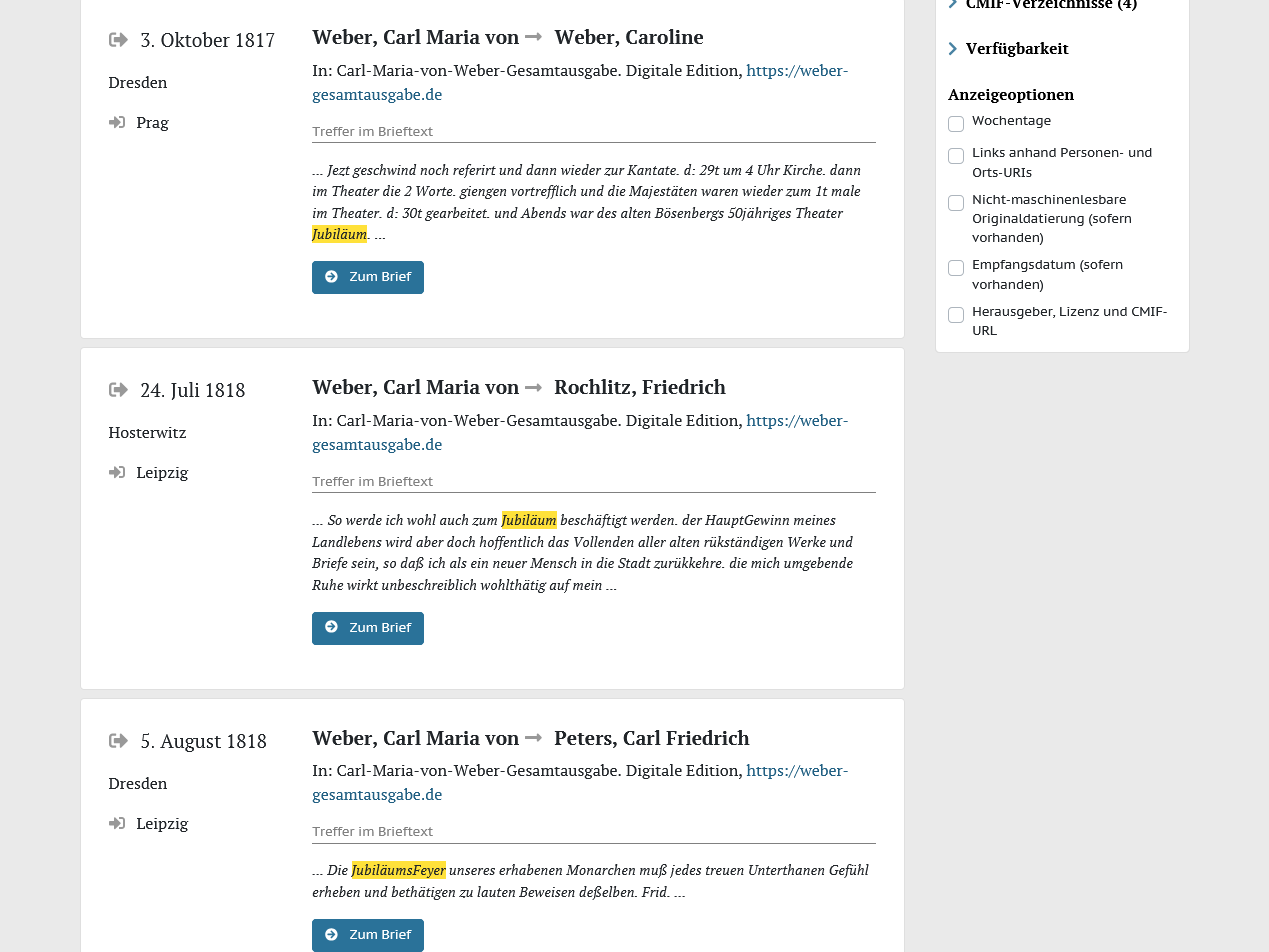
Trefferanzeige der Suche nach „Jubiläum*“ in correspSearch. Über den Textsnippets ist markiert, ob es sich um Treffer im Regest, dem Brieftext oder dem Herausgeberkommentar handelt
Zum anderen kann correspSearch nun neben den Metadaten auch die Volltexte der edierten Briefe harvesten, aggregieren und zur Recherche bereitstellen (z.B. für eine Suche nach “Jubiläum*”). Dabei wird im CMIF lediglich die URL zum TEI-XML-Volltext des jeweiligen Briefes angegeben und beim Ingest der Metadaten von dort bezogen. Digitale Editionen, die ihre Daten sowieso schon via API anbieten, können so leicht auch die Volltexte für correspSearch bereitstellen. Aber auch der Bezug der einzelnen Dateien aus Datendumps (etwa auf GitHub oder Zenodo) ist technisch grundsätzlich möglich. Beim Ingest werden TEI-Grundstrukturen ausgewertet und im Suchergebnis entsprechend angezeigt: So können Recherchierende Treffer im (originalen) Brieftext von denjenigen im Herausgeberkommentar oder Regest unterscheiden. Derzeit sind nur Texte aus den ersten vier digitalen Editionen recherchierbar, die dankenswerterweise bereits die CMIF-Schnittstelle entsprechend erweitert haben (u.a. Weber-Gesamtausgabe und Dehmel digital). Die Menge der im Volltext durchsuchbaren Briefe werden unter dem Suchschlitz der Volltextsuche angezeigt.
Neben der Volltextsuche werden die Suchfunktionen demnächst auch noch um eine weitere ergänzt: So kann man dann nicht nur nach Korrespondenzpartner:innen suchen, sondern auch nach erwähnten Personen. Die Funktion ist bereits fertig implementiert und wird in Kürze freigeschaltet. Sie basiert – wie die Volltextsuche – auf der Erweiterung des CMIF in Version 2 (Proposal, vgl. auch Dumont et al. 2019).
Mit der Version 3.0 von correspSearch wurde auch die API um eine weitere Schnittstelle erweitert: ab sofort können die Daten auch über einen SPARQL-Endpoint abgefragt werden. Dieser kann dankenswerterweise auf der Plattform lod.academy, die von der Akademie der Wissenschaften und der Literatur Mainz betrieben wird, angeboten werden. Das aktuelle RDF-Datenmodell ist dort ebenfalls dokumentiert. Zu beachten ist, dass der SPARQL-Endpoint derzeit noch als Betaversion betrieben wird und sich auch noch Änderungen am Datenmodell ergeben können.
Der Datenbestand konnte diesen Sommer auch wieder einen neuen Stand erreichen. Vor allem durch die Datenbeiträge aus der Editions- und Forschungscommunity, aber auch aus dem Kooperationsprojekt PDB18 (siehe dazu weiter unten) können aktuell über 270.000 Briefversionen recherchiert werden.
Bleibt alles anders
Das DFG-Projekt correspSearch – Briefeditionen vernetzen ist nun zu Ende gegangen, der Webservice wird aber durch die BBAW dauerhaft weiterbetrieben (BBAW 2023, 6). Außerdem läuft derzeit noch das DFG-Kooperationsprojekt Der deutsche Brief im 18. Jahrhundert (PDB18), das zusammen mit dem Interdisziplinären Zentrum für die Erforschung der Europäischen Aufklärung an der Universität Halle und der ULB Darmstadt durchgeführt wird. Ziel des Projekts ist es, eine Datenbasis und ein kooperatives Netzwerk zur Digitalisierung und Erforschung des deutschen Briefes in der Zeit der Aufklärung aufzubauen. Im Fokus des Projekts steht die Retrodigitalisierung bzw. Metadatenerfassung von gedruckten, abgeschlossenen Briefeditionen (Décultot et al. 2023).
Darüber hinaus wird der Webservice im PDB18-Teilprojekt an der BBAW um einige zusätzliche Funktionen erweitert (z.B. die Filter “Datenset” und “Verwendete Sprache”). Die wichtigste Entwicklung wird allerdings csRegistry werden. Mit csRegistry wird es möglich sein, für einen Brief (als “abstrakte” Entität) eine eindeutige URI zu vergeben und unterschiedliche Editionen dieses Briefes damit zu verknüpfen. Dadurch wird es in Zukunft möglich sein, verschiedene Editionen zu ein und demselben Brief in correspSearch anzeigen zu können bzw. diese “doppelten” Nennungen bei Bedarf aus den Daten herauszufiltern – etwa für die Netzwerkanalyse.
So wird die Zukunft noch ein paar Neuerungen für correspSearch bringen. Hoffentlich aber auch weiterhin viele neue digitale Briefverzeichnisse als CMIF, die den Datenbestand weiter anwachsen lassen. Denn auch wenn schon eine erkleckliche Menge an edierten Briefen in correspSearch nachgewiesen ist, die Masse der insgesamt edierten Briefe (allein im deutschsprachigen Raum) ist noch sehr viel größer. Daher ist auch ein Dienst wie correspSearch ohne die vielen großen und kleinen Datenlieferungen durch Editionsvorhaben, Wissenschaftler:innen und Institutionen nutzlos. Wir möchten uns daher an dieser Stelle für die zahlreichen Datenspenden der letzten 10 Jahre ganz herzlich bedanken. Und wer noch (oder wieder) Daten bereitstellen möchte, findet unter “Mitmachen” auf correspSearch.net alle weiteren Informationen.
Literatur
Berlin-Brandenburgische Akademie der Wissenschaften. 2023. “Das Leitbild Open Science der Berlin-Brandenburgischen Akademie der Wissenschaften.” urn:nbn:de:kobv:b4-opus4-37530.
Décultot, Elisabeth, Stefan Dumont, Katrin Fischer, Dario Kampkaspar, Jana Kittelmann, Ruth Sander und Thomas Stäcker. 2023. “PDB18: The German Letter in the 18th Century.” [Poster]. Encoding Cultures – Joint MEC and TEI Conference. Paderborn 2023. https://hcommons.org/deposits/item/hc:59731/
Dumont, Stefan. 2018. “correspSearch – Connecting Scholarly Editions of Letters.” Journal of the Text Encoding Initiative 10. https://doi.org/10.4000/jtei.1742.
Dumont, Stefan, Ingo Börner, Jonas Müller-Laackman, Dominik Leipold, Gerlinde Schneider. 2019. Correspondence Metadata Interchange Format (CMIF). In: Encoding Correspondence. A Manual for Encoding Letters and Postcards in TEI-XML and DTABf. Hg. v. Stefan Dumont, Susanne Haaf, and Sabine Seifert. URL: https://encoding-correspondence.bbaw.de/v1/CMIF.html URN: urn:nbn:de:kobv:b4-20200110163712891-8511250-2
Stadler, Peter. 2014. “Interoperabilität von Digitalen Briefeditionen.” In Fontanes Briefe Ediert, edited by Hanna Delf von Wolzhagen, 278–87. Fontaneana 12. Würzburg: Königshausen & Neumann.
Stadler, Peter, Marcel Illetschko, and Sabine Seifert. 2016. “Towards a Model for Encoding Correspondence in the TEI: Developing and Implementing <correspDesc>.” Journal of the Text Encoding Initiative [Online] 9. https://dx.doi.org/10.4000/jtei.1742.
Update 10.09.2024: Hinweis auf Wikipedia-Vorlage für correspSearch ergänzt; Tippfehler korrigiert. Update 13.09.2024: Hinweis auf CMIFerator ergänzt.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 24. Juni 2024, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Marie Flüh (Uni Hamburg) und Mareike Schumacher (Uni Stuttgart)
In unserem Vortrag zeigen wir anhand von zwei Fallstudien, wie die Klassifikation von Genderaspekten in literarischen Texten mithilfe der Methoden der Computational Literary Studies umgesetzt werden kann. Ausgehend von der Frage, was typische Genderdarstellungen sind und wann diese brüchig werden, untersuchen wir unterschiedliche Korpora: Im Fokus dieses Vortrags steht sowohl ein historisches Korpus mit Texten, die von Simone de Beauvoir anlässlich ihrer Studie “Das andere Geschlecht” (1949) analysiert wurden, als auch ein zeitgenössisches Korpus mit den Romanen der Harry-Potter-Serie (1997–2000). Mit der analytische Reise vom “anderen Geschlecht” nach Hogwarts geben wir Einblicke in unser Forschungsprojekt m*w/DISKO und zeigen eine genre- und zeitunabhängige Überrepräsentation männlicher Figuren-Referenzen. Dieser steht ein kleinerer Teil “anderer” Genderrepräsentationen gegenüber, die nicht ausschließlich als weiblich klassifiziert werden können. Anstelle einer binären Darstellung von Gender offenbart sich so ein aus mindestens drei Komponenten bestehendes “Gegengewicht” aus weiblichen, neutralen und diversen Figuren-Referenzen.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
im Namen des Konsortiums Text+ der Nationalen Forschungsdateninfrastruktur (NFDI) und des ediarum-Teams an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) laden wir Sie herzlich zum nächsten virtuellen ediarum.MEETUP mit einem Projektbericht aus Würzburg ein:
am Montag, dem 10. Juni 2024, 11:00 Uhr s.t.
Das Zentrum für Philologie und Digitalität der Universität Würzburg betreut die technischen Aspekte verschiedener digitaler Editionsprojekte. Eine der Grundlagen hierfür stellt das ediarum-Ökosystem dar. Claudia Esch und Yannik Herbst präsentieren den dazu verwendeten Workflow.
Zunächst werden das Portfolio des ZPD und der allgemeine Workflow vorgestellt, bevor spezifische Problemstellungen und Lösungsansätze, die sich in der praktischen Arbeit mit ediarum ergeben, diskutiert werden. Dazu zählt beispielsweise die Frage nach der Versionierung mit eXist-DB und Github sowie die Herausforderungen bezüglich CI/CD.
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/nad-mge-0rq-ufp erreichbar.
Das ediarum.MEETUP ist primär für DH-Entwickler:innen gedacht, die sich zu spezifischen ediarum-Entwicklungsfragen austauschen wollen, jedoch sind auch ediarum-Nutzer:innen und Interessierte herzlich willkommen.
Wir freuen uns auf zahlreiches Erscheinen!
Viele Grüße Nadine Arndt im Namen der ediarum-Koordination
Die Berlin-Brandenburgische Akademie der Wissenschaften (BBAW) ist eine Vereinigung von Wissenschaftlerinnen und Wissenschaftlern mit einer über 300-jährigen Geschichte, die Aufgaben der Gesellschafts- und Politikberatung wahrnimmt und den Dialog zwischen Wissenschaft und Gesellschaft fördert. Ihr wissenschaftliches Profil ist vor allem geprägt durch langfristig orientierte Grundlagenforschung in den Geistes-und Kulturwissenschaften.
TELOTA – IT/DH ist seit 2001 die Digitalisierungsinitiative und seit 2019 das Digital-Humanities-Referat der BBAW. Seine Aufgabe ist es, Werkzeuge zu entwickeln, mit denen die Forschungsergebnisse der Akademie digital erarbeitet, dokumentiert und präsentiert werden können. Dabei steht der Einsatz nationaler und internationaler Standards aus dem Umfeld der Digital Humanities für die Dokumentation und Nutzung wissenschaftlicher Arbeitsergebnisse im Mittelpunkt. Auf diese Weise können die umfangreichen Wissensbestände der Akademie nachhaltig für die Forschung und die interessierte Öffentlichkeit auf der ganzen Welt nutzbar gemacht werden.
Die Akademie sucht für ihr Referat TELOTA – IT und Digital Humanities zum frühestmöglichen Zeitpunkt einen
wissenschaftlicher Mitarbeiter (m/w/d)
im Bereich Digital Humanities und Forschungssoftwareentwicklung für Digitale Editionen im Umfang von 100 % der regelmäßigen wöchentlichen Arbeitszeit. Die Stelle ist vorerst befristet auf 24 Monate (ggf. teilbar)
Ihre Aufgaben:
Entwurf, Entwicklung und Anpassung von zentralen, digitalen Forschungswerkzeugen und -umgebungen der BBAW
Entwurf und Entwicklung von Daten- und Programmierschnittstellen (APIs) zur Visualisierung und Vernetzung von Forschungsdaten
Weiterentwicklung digitaler Methoden unter Einsatz aktueller Technologien wie Machine Learning oder Knowledge Graphs
Dokumentation der Entwicklungsarbeiten
Mitarbeit bei der Antragstellung und Berichterstattung von Projektanträgen im Rahmen von regionalen, nationalen und internationalen Forschungsförderungen
Präsentation der Arbeits- und Forschungsergebnisse auf einschlägigen Konferenzen und Workshops
Nachgewiesene Erfahrungen auf dem Gebiet der Digital Humanities
Nachgewiesene Erfahrung in der Entwicklung von Forschungssoftware und Programmierschnittstellen (APIs) mit X-Technologien (XML, XPath, XQuery und XSLT) oder mit einer anderen Programmiersprache (z.B. PHP oder JavaScript)
Bereitschaft zur Einarbeitung in neue Technologien und digitale Methoden, z.B. Machine Learning oder Knowledge Based System
Wünschenswert sind Erfahrungen im Einsatz und in der Nutzung von KI-Systemen und Machine Learning in den Digital Humanities
Wünschenswert sind Erfahrung mit der Frontend-Entwicklung (HTML, CSS, JavaScript)
Teamfähigkeit und ausgezeichnete Kommunikations- und Organisationsfähigkeit
Was wir bieten:
Eine anspruchsvolle und abwechslungsreiche Tätigkeit in einem engagierten Team an einer lebendigen Forschungseinrichtung
Betriebliche Altersvorsorge und vermögenswirksame Leistungen
Zuschuss zum VBB-Firmenticket
30 Tage Urlaub bei einer Vollzeittätigkeit, zusätzlich 24.12. und 31.12. freigestellt
Attraktive Möglichkeiten zur wissenschaftlichen Weiterentwicklung im aktiven DigitalHumanities-Umfeld der BBAW
Familienfreundliche Arbeitsbedingungen an einem attraktiven Arbeitsplatz in Berlin
Die Vergütung erfolgt nach der Entgeltgruppe E 13 TV-L. Der Dienstort ist Berlin
Die Berlin-Brandenburgische Akademie der Wissenschaften ist bestrebt, den Anteil von Frauen in Bereichen, in denen sie unterrepräsentiert sind, nach Maßgabe des Landesgleichstellungsgesetzes und des Frauenförderplanes zu erhöhen, daher sind Bewerbungen von Frauen ausdrücklich erwünscht. Bewerbungen von Personen mit Migrationshintergrund sind ausdrücklich erwünscht; Bewerbungen von Schwerbehinderten werden bei gleicher Eignung vorrangig berücksichtigt. Weitere Details zum Projekt finden Sie unter www.bbaw.de/bbaw-digital/telota . Ihre Rückfragen können Sie gerne an den Leiter des Referats TELOTA-IT und Digital Humanities, Herrn Alexander Czmiel (czmiel@bbaw.de), richten.
Ihre aussagekräftigen schriftlichen Bewerbungsunterlagen (Motivationsschreiben, Lebenslauf, Zeugnisse) richten Sie bitte möglichst elektronisch in einer PDF-Datei (max. 5 MB) unter der Kennziffer Telota 01 2024 bis zum 16.06.2024 an die
Berlin-Brandenburgische Akademie der Wissenschaften Referat Personal und Recht Ines Hanke Jägerstraße 22/23, 10117 Berlin
Bitte laden Sie Ihre Bewerbungsmappe unter folgendem Link hoch:
Bitte beachten Sie, dass Sie nach dem Upload der Bewerbungsunterlagen zunächst keine separate Bestätigung erhalten und wir erst nach Ende der Bewerbungsfrist zu Ihnen Kontakt aufnehmen werden.
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 29. April 2024, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Christopher Pollin (Universität Graz)
„Prompting is weird. Prompting matters”, schreibt Ethan Mollick, Professor für Innovation, Entrepreneurship und KI an der Wharton School (USA), in seinem Blog. Der Einsatz von künstlicher Intelligenz in den Digital Humanities hat mit den Fortschritten im Bereich der Large Language Models (LLM) eine neue Stufe erreicht. Prompt Engineering, d.h. die Optimierung der Eingabe in ein LLM, um die „besten” Antworten zu erhalten, kann die Ergebnisse des LLM erheblich verbessern – auch wenn es manchmal kurios erscheint, was der „beste” Prompt ist. Insbesondere „Agentic Workflows” bieten weiteres Potenzial, den Output eines LLM deutlich zu verbessern. Darunter wird die Simulation von Agenten durch Modelle wie GPT-4 oder Claude 3 verstanden, die Entscheidungen treffen, Aktionen festlegen, Werkzeuge benutzen und zusammenarbeiten. Der Vortrag diskutiert Prompting Engineering und Agentic Workflows als Arbeits- und Forschungsmethode anhand verschiedener Beispiele aus den Digital Humanities, aber auch aus anderen Disziplinen wie der Psychologie oder Bereichen der Musik- und Bildgenerierung. Durch Prompting Engineering erzielen Modelle wie GPT-4 spannende Ergebnisse in den Bereichen Modellierung, Datengenerierung, Codegenerierung, Datenextraktion oder Datenanalyse. Welche Voraussetzungen müssen geschaffen werden und welche Herausforderungen bringen die neuen Arbeitsmethoden, die sich mit LLMs ergeben, mit sich?