Our guest today is Dr. Vincent F. Scalfani. Vincent serves as the director of research computing services at the University of Alabama Libraries, providing leadership and support for the newly evolving research computing services across the disciplines. Additionally, he serves as subject liaison for chemical sciences and mathematics. Before joining the University of Alabama in 2012, he earned a PhD in chemistry from Colorado State University.
His research interests include chemical information and cheminformatics. Today, we’re going to be talking about a project that has been ongoing, a project that I am just absolutely in love with. It’s the University of Alabama Libraries Scholarly API Cookbook, which is an open-access online book featuring concise code examples or recipes that illustrate how to interact with various scholarly web service APIs.
These APIs enable researchers to automate search queries, customize data sets, and more easily integrate their information workflows into downstream data analysis processes. Launched in 2022, the cookbook is continually enhanced and updated by student programmers at the libraries. Vin and I have been on faculty here at the university libraries for about 13 years.
Season: 5
Episode: 2
Date: 3/2025
Presenter: Vincent Scalfani
Topic: Scholarly API Cookbook
Tags: Coding; Scholarly API research; research computing
I recently gave a workshop for the US Latino Digital Humanities Center (USLDH) at the University of Houston on introductory text analysis concepts and Voyant. I don’t have a full talk to share since it was a workshop, but I still thought I would share some of the things that worked especially well about the session. USLDH recorded the talk and made it available here, and you can find the link to my materials here.
I had a teaching observation when I was graduate student, and one comment always stuck with me. My director told me, “this was all great but don’t be afraid to tell them what you think.” I’ve written elsewhere about how I tend to approach classroom facilitation as a process of generating questions that the group explores together. This orientation is sometimes in conflict with DH instruction, where you have information that simply needs to be conveyed. I had this tension in mind while planning the USLDH event. It was billed as a workshop, and I think there’s nothing worse than attending a workshop only to find that it’s really a lecture. How to balance the generic expectations with the knowledge that I had stuff I needed to put on the table? As an attempt to thread this needle, I structured the three-part session around a range of different kinds of teaching moves: some lecture, yes, but also a mix of open discussion, case study, quiz questions, and free play with a tool.
The broad idea behind the workshop entitled “Book Number Graph” is that people come to text analysis consultations with all varieties of materials and a range of research questions. Most often, my first step in consulting with them is to ask them to slow down and think more deeply about their base assumptions. Do they actually have their materials in a usable form? Is it possible to ask the questions they are interested in using the evidence they have? I built the workshop discussions as though I was prepping participants to field these kinds of research consultations, as though they were digital humanities librarians.
First, the “book” portion of the workshop featured a short introduction to different kinds of materials, exploring how format matters in the context of digital text analysis. We discussed how a book is distinct from an eBook is distinct from a web material, and how all of these are really distinct from the kind of plain text document that we likely want to get to. I used here a hypothetical person who shows up in my office and says, “Oh yeah, I have my texts. I’m ready to work on them with you. Can you help me?” And they will hand me either a stack of books or a series of PDF files that haven’t been OCR’d. I introduced workshop participants to the kinds of technical and legal challenges that arise in such situations so that they’ll be able to better assess the feasibility of their own plans. This all built to a pair of case studies where I asked the participants how they would respond if a researcher came to them with questions for their own project.
With these case studies, I hoped to give participants a glimpse into the real-world kinds of conversations that I have as a DH library worker. For the most part, consultations begin with my asking a range of questions of the researcher so as to help them get new clarity on the actual feasibility of what they want to do. I hoped for the participants to question the formats of the materials for these hypothetical researchers and point out a range of ethical and legal concerns. Hopefully they would be able to ask these questions of their own work as well.
For the second section of the workshop entitled “number,” I gave participants an introduction to thinking about evidence and analysis, distinguishing between what computers can do and the kinds of things that readers are good at. Broadly speaking, computers are concrete. They know what’s on the page and not what’s outside of it. Researchers in text analysis need to point software to the specific things that they are interested in on the page and supplement this information with any other information outside of the text. Complicated text analysis research questions have at their core really simplistic, concrete, measurable things on the page. You are pointing to a thing and counting. For examples of the things that computers can readily be told to examine, we discussed structural information, proximity, the order of words, frequency of words, case, and more.
To practice this, I adapted an exercise that I was first introduced to by Mackenzie Brooks but that was developed by librarians at the University of Michigan. To introduce TEI, the activity asks students to draw boxes around a printed poem as a way to identify the different structural elements that you would want to encode. For my purposes, I put a Langston Hughes poem on the Zoom screen and asked participants to annotate it with all sorts of information that they thought a computer would be capable of identifying.
The result was a beautiful tapestry of underlines and squiggles. Some of the choices would be very easy for a computer: word frequency, line breaks, structural elements. But we also talked about more challenging cases. We know the poem’s title because we expect to see it in a certain place on the page. The computer might be pointed to this this by flagging the line that comes three after three blank line breaks. But what if this isn’t always the case? It was good practice in how to distinguish between the information we bring to the text and what is actually available on the page. We talked about the challenges in trying to bridge the gap between what computers can do and what humans can do, to try and think through how a complicated intellectual question might take shape in a computationally legible form.
Wrapping all this together, I introduced what I called the M.E. test for text analysis research. To have a successful text analysis project you have to have…
Materials that are…
appropriate to your questions and
accessible for your purposes.
You must also have
Evidence that is…
identifiable to you as an expression of your research question and
legible to the tool you are using.
Materials and Evidence. M and E.
M.E.
The next time you sit down to do text analysis, ask yourself, “What makes a good question? M.E. Me!”
Painfully earnest? Sure! But this was a nice little way for me to tie in what I often joke is my most frequently requested consultation topic: imposter syndrome. The M.E. question is both a test for deciding whether or not a text analysis research question is appropriate, but it is also a call for you to recognize that you can handle this work. A nice little way for you to give yourself a pump up, because I believe that these methods belong to anyone. Anyone can handle these kinds of consultations. They’re more art than science at the level we are discussing. You just have to know the correct way to approach them. Deep expertise can come later. If you are too intimidated to get started you will never get there.
From there, I closed the “number” portion of the workshop with a couple more case study prompts. I asked participants to respond to two more scenarios as though someone had just walked into their office with an idea they wanted to try out.
The hypothetical consultation prompts involved, first, an interest in finding the most important characters in a particular Shakespeare play and, second, an interest in space and place in southeastern American literature. In each case, we discussed questions of format and copyright, but we also got to some fairly high-level questions about what kinds of evidence you could use to discuss the research questions. For importance, participants proposed measuring either number of lines for each character or who happens to be onstage for the greatest amount of time. For space and place, we discussed counting place names using Python (a nice way to introduce concepts related to Named Entity Recognition). In each case, my goal was to give the workshop participants a sense of how to test and develop their own research questions by walking them through the process I use when talking with researchers asking for a fresh consultation.
USLDH has shared the recording link, so feel free to check out the recording if you want to see the activities in action. The slides can be found here. And never forget the most important thing to ask yourself the next time you’re working on a text analysis problem:
Datenflut im digitalen Zeitalter – auch die Geisteswissenschaften stehen zunehmend vor der Herausforderung, riesige Datenmengen zu bewältigen. Doch wie können diese Daten sinnvoll genutzt werden, um neue Forschungsperspektiven zu eröffnen? Die neue Workshop-Reihe „We...
When I was 16, I burned my math exams in a bonfire. I remember holding my last ever math exam in front of my friends, on which a 0.25/20 was marked in bright-red ink, and throwing it in the fire. Feeling a rush of excitement, realizing that I will never have to endure math classes ever again. I would never have to be singled-out by my math teacher for being the worst student of the class, probably of the year, potentially of his career, ever again. Now, I look back at my math years with a more acute sense of how coming from an underprivileged background where no one monitors your homework (and checks if you successfully learnt your times table) and how internalizing a gendered form of knowledge from a very early age (you are a girl you will be drawn to humanities) is a recipe – dare I say the components of an algorithm – for mathematical disaster.
When I applied to Praxis, I was fully aware that being awarded the fellowship would be the first step of a healing journey (as dramatic as it might sound), a healing journey in which band-aids have numbers on them, and not just the fathomable computer binary 0 and 1, but also the mean-looking ones, with squared numbers and exponential functions. Praxis would mean confronting myself to coding, which would require confronting myself, to a certain extent, to mathematics. It feels as though Scholar’s Lab people have now become experts in “teaching the math basics you will need to understand for you to engage in coding” to Humanities people with a varying degree of proficiency in arithmetic. From Shane’s goofy-looking dog Rocky on the first slide of the history and genealogy of computing to constant reassurance, we were presented with a progressive complexity which made our first assignment, “write out in plain English an algorithm to sort a deck of cards” a funny and appealing game.
Now, I have to be honest and confess that I cried on my way out of the Scholar’s Lab, after this first “Introduction to Data” session. Not because someone said something wrong or made me feel bad – of course not. But because in front of this whiteboard on which were written so many numbers, I felt myself going back in time ten years earlier, blankly staring at the whiteboard in my math class, not understanding a single thing. Not because I did not want to (or perhaps unconsciously), but because I was utterly unable to comprehend what was going on. As if I was stuck in a fever dream where whatever was written down felt like a language from outer space and where someone would just keep repeating “how can you not understand this?”.
Then, I remembered the “So you want to be a wizard?” zine that Shane handed out and had us read, and its writer Julia Evans’s positive reframing of difficulty. In this programming zine, she presents bugs as learning opportunities. Bob Ross would have added – “happy accidents”. Somehow, crying after this “Introduction to Data” was a personal necessity. I needed to get my math trauma out of the way, and the deep feelings of shame, guilt, and incompetence that have been hindering me for years. I have no illusion as I know I won’t become Ada Lovelace, Elizabeth Smith Friedman or Mavis Batey – I will still be bad at math, because my brain must have rewired itself differently. But now that we are being invited to learn, fail and learn from apparent failure, I know that I will hold my head high up and try, fail, learn and try again, differently. Praxis has allowed me to move on and make peace with the teenager in me who still feels the burning shame of being the last at something. Now, I can tell her that a bad math average makes for the best potential for growth. 0.25/20 is not so bad.
This fall, KU Leuven ICTS is offering a selection of online workshops focused on various softwares for working with data. If you have been hoping to learn more about Excel for use with quantitative data, LaTeX for more flexibility when it comes to the format of your academic writing, or Python for more advanced data science techniques (workshop requires knowledge of a previous programming language such as R), then you might be interested in one of the following workshops!
What? By means of practical examples you will quickly become familiar with the basic techniques of Excel: Input, Editing, Formatting, Simple calculations.
For whom? Anyone who is interested, regardless of their statute (PhD student, postdoc, scientific collaborator..). No prior knowledge of Excel required, but some experience with other Office programmes (Word, Outlook) comes in handy.
What? This training session introduces the programming language to participants who have programming experience with other programming languages such as R, MATLAB, C/C++ or Fortran.
For whom? Anyone who is interested and who already has experience in another programming language (e.g. R).
I want to apply some text analysis tools to explore questions around a set of podcast interviews. There’s a webpage that lists links to transcripts of these interviews, one link per podcast episode text file. Because there are many episodes (over a 100?), I don’t want to manually click each link to download the episode’s transcript file.
Instead, I followed a Programming Historian lesson by Ian Milligan about the command-line utility wget. The lesson helped me understand how to customize wget’s options so it downloads each transcript file for me into a convenient folder, without overloading the website’s servers.
Here’s the command I used (after installing a couple things that Milligan’s lesson walks you through):
wget -r -l 3 ––random-wait -w 10 --limit-rate=20k [URL of folder containing desired files to download]
That command consists of the tool name (wget), a bunch of options modifying how the tool downloads files, and the URL you want to be downloading from. The options I chose to fit my particular webpage of interest:
-r says to follow links on the URL I provide to other links
-l 3 says to follow each link to 3 pages away from the initial URL I provided
-w 20 adds a 20 second wait between server requests
––random-wait was in response to my initial wget attempts producing a “ERROR 429: Too Many Requests.” message and not downloading files; it varies the wait time by 0.5 to 1.5 times the length provided with the -w 10 option above
--limit-rate=20k sets the maximum download speed to 20kb/s to be nice to the site’s bandwidth (initially tried -w 2; that allowed downloading of ~30 files then ran into 429 error again)
The files are now downloading in the background! My next step will be using another command-line utility, pandoc, to convert the transcript files from one file type (MS Word) to another file type friendlier to text analysis.
If you’re interested in automating downloads rather than manually clicking-saving a bunch, you might check out my post from 5(!) years ago on automating taking screenshots of webpages using a list of URLs (which I used to get a folder of screenshots of all my faved tweets).
If you’re interested but have never used the command line, Programming Historian has a peer-reviewed, free online tutorial aimed at humanities/cultural heritage folks who want to learn command line use. I highly recommend PH’s website; not only is every lesson created with communal care (author[s], editor, multiple reviewers), the lessons are aimed at humanities-ish folks (the things that might interest you, the things you might be excited to learn how to do with code), and the lessons are written in a very novice-friendly style (no assumptions you already know things; or the advanced lessons point you to the earlier lessons you’ll need to complete before you can comfortably follow them).
Das Forschungsprojekt „Echoes from the Past: Unveiling a Lost Soundscape with Digital Analysis” (2023-2026), angesiedelt an der Universidade NOVA de Lisboa, untersucht die Musik des Mittelalters mit digitalen Methoden. Auf interdisziplinärem Terrain verspricht es somit neue Erkenntnisse für die historische Musikforschung und Musiktheorie, die Digital Humanities (Computational Musicology) und das Music Information Retrieval (MIR) gleichermaßen. Teil des Projekts war die einmalig stattfindende Konferenz „ECHOES24“, auf der ich Ende Juni erste Ergebnisse meines Promotionsprojekts vorstellen durfte. Sie führte weltweit führende Wissenschaftler:innen des Forschungsbereichs, ebenso wie Promovierende, Early Career Scholars und Professor:innen in Lissabon zusammen, um über „Digital Technologies Applied to Music Research: Methodologies, Projects and Challenges“ zu diskutieren.
In meiner Promotion beschäftige ich mich im Rahmen einer digitalen Korpusstudie mit Polymetrik und metrischen Irregularitäten in den Kompositionen Hugo Distlers, Béla Bartóks und Paul Hindemiths. (Polymetrik nennt man – ganz allgemein – gleichzeitig auftretende, unterschiedliche Taktarten, siehe Abb. 1.) Darauf aufbauend möchte ich ein eigenes Bayessches Modell für Polymetrik entwickeln. Solche metrisch komplexen Strukturen werden in der aktuellen Forschung zur computergestützten Musikwissenschaft noch weitgehend außen vor gelassen, unter anderem da deren Modellierung und computergestützte Analyse bestehende Ansätze und Codierungsformate an ihre Grenzen führt. Mit meinem Forschungsvorhaben möchte ich diese Lücke schließen und mittels einer ergebnisoffenen Grundlagenforschung einen signifikanten Beitrag zur Analyse komplexer Musik, insbesondere des 20. Jahrhunderts, leisten. Daher interessierten mich explizit die auf der Konferenz behandelten Themenbereiche „Key challenges in applying digital technologies to music research” sowie „Music encoding”.
Abb. 1: Beginn von Hugo Distlers Motette „O Heiland, reiß die Himmel auf“ aus Der Jahrkreis op. 5 (1933). Jede Stimme wird in ihrer je eigenen Metrik ausgestaltet; die Taktarten wechseln sehr häufig.[1]
Herausforderungen bei der Codierung von Polymetrik
Für meine Promotion und beginnende wissenschaftliche Karriere stellte diese Konferenz ein wichtiges Sprungbrett dar. Dort konnte ich zum ersten Mal mein eigenes Forschungsprojekt in einem öffentlichen Vortrag international präsentieren. Explizit stellte ich die Möglichkeiten und Grenzen der Codierung von Polymetrik in verschiedenen Musikcodierungsformaten vor (Folien; Videomitschnitt, leider ohne Ton). Zu meiner Freude war mein Vortrag sehr gut besucht und das Publikum aufmerksam interessiert. Mein Befund, dass Polymetrik in den bestehenden Formaten MusicXML, MEI und Humdrum (noch) nicht originalgetreu codiert werden kann, überraschte die Anwesenden. An den drei Konferenztagen konnte ich mich darüber in vielen Gesprächen austauschen – deshalb wurden gerade die Kaffeepausen zu den wichtigsten Zeiten für mich. Wir haben auch schon gemeinsam erste Lösungsansätze diskutiert, die aufgrund des starken Alte-Musik-Fokus der Konferenz neben dem modernen Westlichen Notationssystem dankenswerterweise auch die Mensuralnotation einschlossen – ein vielversprechender Ansatz!
Abb. 2: Deckblatt meines Konferenzvortrags bei der ECHOES24
Abb. 3: Interessiert-lockere Atmosphäre während des Vortrags
Musikforschung zwischen Gaga und Bioinformatik
Insgesamt hörte ich in den drei Tagen 15 Vorträge sowie zwei Keynotes, und besuchte zwei Workshops: in toto eine Tour d’Horizon durch die digitale Musikforschung. In Parallel Sessions fanden gleichzeitig Vorträge in den Bereichen „Digital Early Music“ und „Digital Musicology“ statt. Hier eine Auswahl:
Tillman Weyde (City, University of London) stellte kollaborative Tools in der Jazz-Forschung vor, die synergetisch Methoden des Music Information Retrieval (MIR) und des maschinellen Lernens kombinieren. Insbesondere besprach er seine JazzDAP Studien, die auf den bekannten Arbeiten zur Dig That Lick Database sowie dem Jazzomat Research Project aufbauen.
Das Warschauer Fryderyk-Chopin-Institut um Marcin Konik, Jacek Iwaszko und Craig Sapp stellte das beeindruckende Projekt „Polish Music Heritage in Open Access“ (siehe Polish Scores) vor: ein Online-Repositorium polnischer Musik aus sechs Jahrhunderten, das rund 25.000 Manuskripte und Partituren mit insgesamt einer halben Million Seiten Musik umfasst. Die digitalen Editionen enthalten Codierungen im Humdrum-Format, die mittels IIIF-Koordinaten mit den originalen Partiturseiten verbunden sind.
Andreas Waczkats (Göttingen) forscht zur Rekonstruktion des Klangs einer Londoner Orgel, auf der Georg Friedrich Händel einst spielte. Dem Klangideal nähert sich Waczkat mithilfe des Tools „SOUND“ (FU Berlin), das 3D Sound-Daten verwendet, sowie der VR-Anwendung „Virtual Acoustics“ (RWTH Aachen).
Maria Navarro Cáceres (Salamanca) untersuchte in 20.000 irischen und spanischen volkstümlichen Melodien die Verwendung verschiedener Kirchenmodi. Interessant: Vor allem im spanischen Raum ist Phrygisch sehr beliebt!
Tim Eipert (Würzburg) und Francisco Camas (Madrid) verwendeten in Ihrer Forschung zu mittelalterlichen Tropen unabhängig voneinander bioinformatische Methoden der Phylogenese, um die Provenienz verschiedener Gesänge mit ihren musikalischen Stilen abzugleichen. Daraus ließ sich eine „Stammesgeschichte“ verschiedener mittelalterlicher Gesänge ableiten. Insbesondere diese beiden Forschungsprojekte stießen auf großes Interesse, da hier sowohl die Integration in die historische Musikforschung als auch der erwartete Erkenntnisgewinn sehr vielversprechend ist.
Ganz allgemein war der Wunsch nach Interdisziplinarität im Plenum deutlich spürbar. In diesem Sinne warb Cory McKay (Marianopolis College) für mehr Kommunikation und Offenheit bei Kooperationen zwischen der Musikwissenschaft und der Informatik bzw. dem MIR. Seinem Vortrag stellte er die methodologisch entscheidende Frage voran, „how to make musicological sense out of computer data“. Neben der gründlichen Vor- und Aufbereitung musikalischer Daten, um Biases zu vermeiden, trügen vor allem Visualisierungen zum Verständnis bei.
Adam Knight Gilbert (USC, Los Angeles) entwickelte gemeinsam mit Andrew Goldman (Indiana University) den GaGA-(Gilbert-and-Goldman)-Algorithm, mit dem sie Symmetrien in Kontrapunktwerken des 15. Jahrhunderts identifizieren können. Auf diese Weise untersuchten sie verschiedene Formen musikalischer Palindrome („Inversodrome“, „Crabindrome“) in Chansons von Gilles Binchois sowie in Messen und Motetten Johannes Ockeghems. Sie stellten die Frage in den Raum, inwieweit solche Symmetrien kompositorisches Spiel oder kontrapunktisches Derivat sind.
Keynotes: Schon viel erreicht und noch mehr zu tun
Besonders beeindruckend war die abendliche Keynote von Ichiro Fujinaga (McGill University), der seit 40 Jahren Pionierarbeit auf dem Gebiet der Optical Music Recognition (OMR) leistet. Humorvoll veranschaulichte er die Errungenschaften in diesem Bereich und ermutigte, die aktuellen Herausforderungen anzugehen. Er warb insbesondere für das Konzept der „Mechagogy“, dem Machine Teaching als Fähigkeit, Computer und Künstliche Intelligenzen richtig zu „erziehen“ und somit leistungsstärker und lösungsorientierter zu machen. An dieses Konzept konnten auch die Kunstsoziologen Denise Petzold und Jorge Diaz Granados (Maastricht) anschließen, die zur Diskussion über die Frage anregten, ob digitale Technologien als Musikinstrumente angesehen werden sollten.
In der zweiten Keynote mit dem Titel „Sustaining Digital Musicology“ plädierte Jennifer Bain (Dalhousie University) für mehr Kooperation innerhalb der Musikforschung, um Forschungsdaten langfristig erhalten zu können. Mit erschreckenden Zahlen aus den vergangenen drei Jahren warnte sie vor Datenverlust durch Cyberattacken. Das Rechenzentrum der Dalhousie University etwa (mit ihren 20.000 Studierenden) blockiert täglich 800.000 Spam-Mails. Die British Library arbeitet seit einem verheerenden Hacker-Angriff vergangenen Oktober immer noch an der Wiederherstellung wertvoller Daten. Leider seien es häufig DH-Projekte, die den Weak Link ins Unisystem darstellen, da ältere Online-Projekte oftmals keine Updates mehr durchlaufen. Der Nachhaltigkeit solcher Projekte abträglich seien zudem schlechte Dokumentation und ein erschwerter Zugang zu Fördermitteln. Was also tun? Zielführend seien gemeinsame, interdisziplinäre Projekte, die auf bestehenden Tools aufbauen, und vor allem gemeinsame Metadaten-Standards innerhalb der Community. Jennifer Bain schloss zuversichtlich: „The future of Digital Musicology looks bright. Let us be more intentional.”
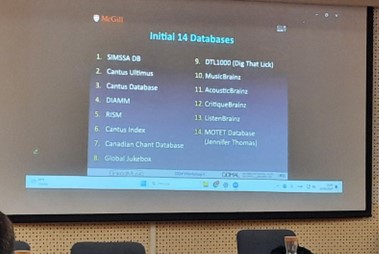
Ein solches verheißungsvoll-intentionales Projekt stellte Ichiro Fujinaga abschließend in einem interaktiven Workshop vor: LinkedMusic. Dessen Ziel ist es, von einer Website aus in verschiedenen Musikdatenbanken suchen zu können, und zwar ausdrücklich auch in anderen Sprachen als Englisch. Die Herausforderung dabei: Die 14 verbundenen Datenbanken haben 14 inkompatible Datenbankstrukturen. Integrierte Bestandteile von LinkedMusic sind u. a. Linked Open Data, Semantic Web (für Interoperability und Data Integration), der RDF-Standard, die SPARQL Language sowie OpenRefine zur Bereinigung und Konvertierung von Daten.
Abb. 4: 14 Datenbanken in LinkedMusic
Quintessenz
Was nehme ich von der Konferenz mit? Einen vollen Kopf, eine Liste an Mailadressen, viele offene Google-Tabs und noch mehr offene Fragen, etliche Forschungsideen und sogar schon Angebote für Forschungsaufenthalte an der Stanford University und der McGill University. In jedem Fall waren meine Erlebnisse auf der ECHOES24 überaus positiv, vor allem geprägt durch das angenehme Konferenzklima (sowohl zwischenmenschlich als auch meteorologisch). Dazu beigetragen haben allem voran das ehrliche Interesse der Teilnehmenden und die wertschätzende Feedback-Kultur, die in dieser Form insbesondere für Promovierende wünschenswert ist.
Abb. 5: Ein Kalauer am Ende des Vortrags leitete zur Diskussion über.
Der Autor dankt dem DHd-Verband für die Ermöglichung der Konferenzteilnahme durch das Reisekostenstipendium für DH-nahe Tagungen (Sommer 2024).
Kontakt: lucas.hofmann@uni-wuerzburg.de
[1] Hugo Distler, „O Heiland, reiß die Himmel auf“, in: Der Jahrkreis op. 5, Kassel 1933, S. 8, Beginn.
Wir freuen uns sehr auf den gemeinsamem Hackathon zu mittelhochdeutschen Texten und LLMs mit dem DFG-Netzwerk Offenes Mittelalter und laden zu einem ersten Treffen am kommenden Montag, den 05.02.2024 von 14.00-19.00 Uhr ein. Wir...
Do you find yourself wishing you could learn a new digital skill like R or Python, but just cannot seem to carve out the time in your schedule? Do you get started but then find yourself stuck and in need of advice? If so, the Digital Skills Space might be a good fit for you!
The Digital Skills Space is a regular space to learn, practice and share tips to work with digital data and enhance reproducible research. The idea is to carve out a space in busy schedules for investing in digital skills, from managing and processing data, to exploring it with tables and plots, to reporting it in a reliable and reproducible way.
If you would like to see what has been covered in previous sessions or read more about the initiative, you can visit the DigiSkills website.
The Digital Skills Space is organized within the Linguistics Department of the Faculty of Arts, KU Leuven by Mariana Montes.
Sessions take place every Friday from 11:00 to 13:00.