Digital images are in constant motion. They traverse various platforms, feeds, databases, and archives, often reappearing in modified forms. Through my research on digital art, I have recognized this phenomenon as more than a mere feature of online dissemination. It constitutes both a methodological challenge and a perceptual issue.
What appears to be a single image may, in actuality, exist as a collection of various versions: cropped, compressed, recoloured, or reposted without proper attribution. Although these differences may seem insignificant at first glance, they give rise to a question that is more complex to answer than it initially appears.
Under what circumstances can two images be considered identical?
That question became the basis of my assignment for the CodeLab course in my ongoing Praxis Fellowship Program. Using Python with the ImageHash and Pillow libraries in VS Code, I built a small tool to test how visual similarity might be measured across images that have changed through circulation. What started as an exercise became a way of thinking through something larger: what does it mean for a computer to recognize an image, and does that match what we mean when we say two images are the same?
The approach
The tool uses the imagehash library to compute perceptual hashes and compare images by visual similarity.1 Unlike cryptographic hashing, which changes entirely if even a single byte changes, perceptual hashing captures how an image looks. Two visually similar images should produce similar hashes; unrelated images should not.
After generating the comparison data, I modified the script to export results as JSON and render them as an HTML page. Instead of raw values, the interface ranked each image against the reference, displayed a distance score, and grouped results into categories from “nearly identical” to “different from the original.” The script processed files in the images/ folder, saved results to version_results.json, and generated output in results.html.
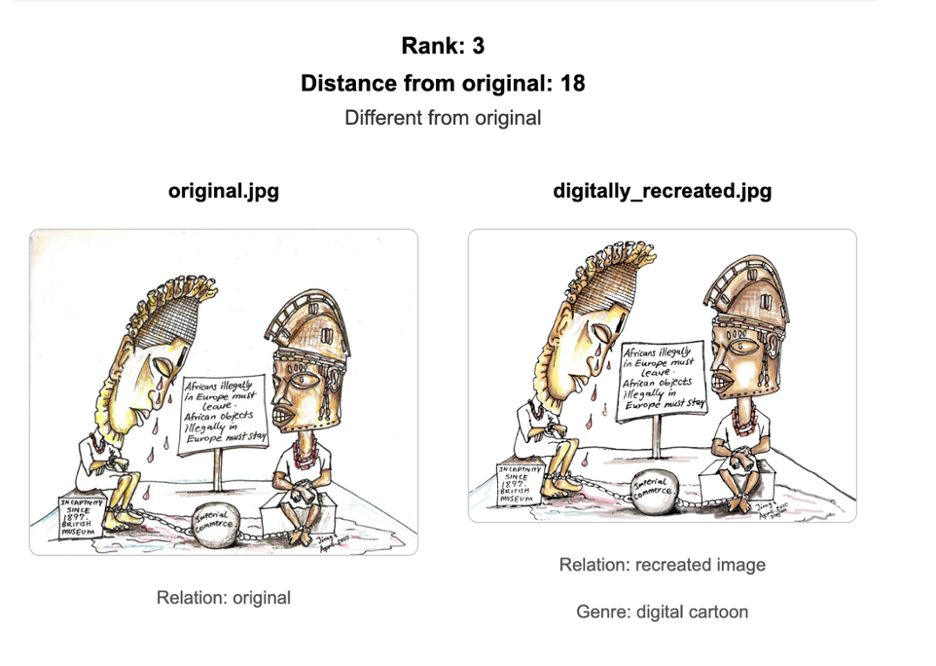
Figure 1. HTML interface showing ranked comparison of image variants against the reference image. See https://jimgaconcept.github.io/image-versioning-demo/
The dataset
The reference image is a digitized hand-drawn cartoon illustration made with pen and ink and watercolor on paper. This detail turned out to matter a great deal. I compared it to two modified copies (resized and compressed), one digitally recreated version, and three visually unrelated images, to test whether the tool could distinguish genuine variants from unrelated works.2
Results
The two modified versions, resized and compressed, both scored between zero and two, confirming their close relationship to the reference. The three unrelated images all scored above 20, well outside any similarity range. The digitally recreated version (Fig. 1) scored 18, placing it in the category that the interface labeled as different from the original.
That score of 18 was the result I did not expect, and the one worth thinking about most carefully.
What the computer sees, and what we see
The recreated image and the original share the same subject, composition, and color palette. A human viewer encountering both would almost certainly recognize them as versions of the same thing. The algorithm did not. Scoring 18, it placed the recreation closer to the unrelated images than to the two modified copies, which scored between 0 and 2.
The reason lies in what each image actually is at the data level. The original is a scan of a physical drawing, and its pixel data carries the texture of its medium: the grain of the paper, the way ink spreads at the edges of marks, the tonal variation of pigment on a physical surface. The digital recreation was built entirely within Photoshop and saved as a JPEG. Even a faithful digital reconstruction is made from digital brushes and algorithmically generated marks. There is no paper grain, no ink bleed. The two images look the same to us, but their underlying data structures are built from entirely different material.
This is a version of what computer vision researchers call the cross-depiction problem: the gap between human visual recognition, which operates on meaning and composition, and machine recognition, which operates on statistical patterns in pixel data. My experiment gave that abstract problem a specific, personal form. What appears identical to the human eye may share almost nothing in common at the data level. The computer is not seeing the image. It is reading a numerical structure, and two images that represent the same thing visually can be built from entirely different data, depending on how and where they were made.
This relates to a broader discourse within the field of digital humanities. As Drucker (2013) has articulated, digitization constitutes not merely a neutral representation but rather a form of interpretation. Factors such as resolution, lighting conditions, and the medium of capture all influence the transformation of an image into data.3 My findings exemplify this argument concretely. The scanned watercolor and the Photoshop recreation are not simply two variants of the same image; rather, they represent two distinct interpretations, which the algorithm processes accordingly.
If we are building archival systems or image databases that rely on computational similarity to group and relate works, we need to ask whose sense of “the same image” is being encoded. A tool trained on pixel-level data will consistently separate a scanned physical artwork from its digital recreation, not because they are different images in any humanistic sense, but because they are different kinds of data.
Limitations and what comes next
Perceptual hashing assesses visual similarity at the data level. It does not establish authorship, confirm provenance, nor consider contextual factors. Outcomes may also differ based on the specific hashing algorithm employed, as various implementations assign different weights to visual features. This tool serves as one component within a broader interpretive framework, rather than substituting human judgment.
This assignment illuminated a perception that is both straightforward and profound. It is evident that the computer and the human eye do not observe the same aspects, even when examining the same image. The disparity between data and meaning represents the realm where the most compelling inquiries within digital art history reside. As Burdick et al. (2012) suggest, the significance of computational tools in the humanities lies not in their capacity to resolve questions, but rather in their ability to render certain questions newly answerable.4 This experience has prompted a question I was previously unaware of having.
The live output and ranked visualization are at the project web interface. Full code is on GitHub.
-
The imagehash library was developed by Johannes Buchner: https://github.com/JohannesBuchner/imagehash. Distance between hashes is computed using Hamming distance. See Hamming, R.W. (1950). Error detecting and error correcting codes. Bell System Technical Journal, 29(2), 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x ↩
-
The distance thresholds used (0 for near-identical, 1–5 for minor modification, 6–10 for significant transformation, above 10 for visually distinct) are derived from standard imagehash benchmarks and calibrated through iterative testing against the dataset. ↩
-
Drucker, J. (2013). Is there a “digital” art history? Visual Resources, 29(1–2), 5–13. doi:10.1080/01973762.2013.761106. The argument that digitisation is interpretive rather than neutral runs throughout the article and is developed across pp. 5–8. ↩
-
Burdick, A., Drucker, J., Lunenfeld, P., Presner, T., and Schnapp, J. (2012). Digital_Humanities. MIT Press. The claim is consistent with the book’s central thesis; p. 14 is the closest anchor. ↩




 (New version on the left.)
(New version on the left.)