DEEP INTO SEOUL PROJECT는 경성 디지털 문학지도 공동연구팀이 개발한 디지털 문학 플랫폼입니다. 저희 연구팀은 한국 근대문학 텍스트에서 공간 정보를 체계적으로 추출하고, 이를 바탕으로 디지털 문학지도를 구축해 온 전문 연구진으로, 디지털 인문학 방법론을 통해 문학 연구의 객관성과 재현성을 높이는 한편, 학술 성과를 대중과 공유하는 데 주력해 왔습니다.
DEEP INTO SEOUL PROJECT는 현대의 구글 지도 위에 근대 시기의 정밀 지도인 <대경성부대관>을 중첩하고, 그 위에 2,900여 편의 한국 근대소설에 등장하는 장소 정보를 집적한 플랫폼입니다. 이를 통해 160여 개의 동(洞) 단위 지명, 250여 개의 문학 랜드마크 등을 지도 위에서 확인할 수 있습니다.
1) 인터랙티브 문학지도 〈대경성부대관〉을 현대 구글 지도와 중첩하여 1930년대 경성을 정밀하게 복원하였습니다. 지도 위의 랜드마크를 클릭하면 해당 장소가 등장하는 작품과 구체적인 장면을 바로 읽을 수 있으며, 이광수·염상섭·박태원 등 200여 명의 근대 작가가 각기 다른 시선으로 그려낸 경성의 모습을 비교해 볼 수 있습니다.
2) 네트워크 시각화 작가–장소–작품의 관계를 시각적 네트워크로 제시하여 복잡한 문학적 연결 구조를 한눈에 파악할 수 있습니다. 이를 통해 250여 개의 주요 장소와 7,000여 개의 문학 장면이 어떻게 연결되는지 확인할 수 있으며, 특정 장소를 선택하면 해당 장소가 등장하는 작품의 장면을 즉시 검색해 볼 수 있습니다.
3) AI 기반 텍스트 분석 구글 Gemini를 활용하여 소설 속 인물의 이동 경로를 자동으로 분석하고, 이를 지도 위에 시각화합니다. 또한 작품 속 인물 간의 관계와 감정 변화를 네트워크 그래프로 제시하여 서사의 구조를 보다 입체적으로 이해할 수 있습니다.
4) 근대소설 삽화 아카이브 신문 연재 근대 장편소설에 실린 삽화를 아카이브로 제공하여, 근대 시기의 의상·주거·교통·일상생활을 시각적으로 확인할 수 있습니다. 소설 텍스트와 삽화를 함께 감상함으로써 보다 높은 몰입도의 문학 경험을 제공합니다.
CBDB Desktop & Web is a free and open-source (AGPL-3.0 license) interface built with web technology that provides new ways to use the China Biographical Database (CBDB data is licensed under CC BY-NC-SA 4.0; CBDB schema is separately copyrighted; see licensing). CBDB Web is the same interface but a hosted version at dh-tools.com/cbdb. CBDB Desktop & Web source code is available on GitHub.
《묘법연화경》은 대승불교에서 가장 중요하고 가장 영향력이 깊은 경전 중 하나이며, ‘경중지왕(經中之王)’으로 존칭됩니다. 이 경전은 ‘삼승은 방편이요, 일승만이 구경(궁극)’이라는 사상으로 대승의 중생 평등이라는 자비와 지혜의 함의를 열어 보입니다.
한자 문화권에 유통된 주요 역본으로는 서진(西晉) 시대 축법호(竺法護) 역 《정법화경(正法華經)》, 요진(姚秦) 시대 구마라집(鳩摩羅什) 역 《묘법연화경(妙法蓮華經)》, 수(隋)나라 시대 사나굴다(闍那崛多)와 달마급다(達摩笈多) 공역 《첨품묘법연화경(添品妙法蓮華經)》 세 가지가 있습니다. 이 가운데 구마라집 역본은 문장이 아름답고 유려하며, 깊이 있는 내용을 쉽게 풀어내어 널리 유통되었고, 중국 불교 발전에 심대한 영향을 끼쳤습니다. 《법화경》은 천태종(天台宗)과 같은 중요한 종파를 탄생시켰을 뿐만 아니라, 동아시아 불교 문화권의 사상, 문학, 예술 등 여러 분야에 지대한 영향을 미쳤으며, 오늘날에도 대만 등 지역의 신앙생활에서 중요한 역할을 수행하고 있습니다.
본 데이터베이스는 여러 한역본을 중심으로 하고, 산스크리트어 사본(네팔, 길기트 등 출토본), 티베트어 역본 및 현대 영어 역본 등을 보조 자료로 삼아 언어 간 문헌 대조를 수행합니다. 디지털 기술을 활용하여 완전한 문헌 비교 시스템을 구축하였으며, 이를 통해 다음을 목표로 합니다:
《법화경》의 다각적인 면모 제시: 다양한 역본 간의 차이와 연관성을 밝혀, 연구자들이 《법화경》의 변천과 전파 과정을 심도 있게 이해하도록 돕습니다. 초문화적·학제적 학술 교류 촉진: 국내외 학자들에게 열린 플랫폼을 제공하여 《법화경》의 사상적 정수와 문화적 가치를 함께 탐구하도록 합니다. 《법화경》의 현대적 해석과 응용 도모: 현대 사회에 정신적 지침과 가치관의 준거를 제공하며, 불교 문화의 계승과 발전을 촉진합니다. 본 데이터베이스는 인터넷 플랫폼을 잘 활용하여 《법화경》의 지혜 정수가 널리 전파되어, 전 세계 대중에게 이익이 되도록 하고자 합니다.
법고문리학원(法鼓文理學院) DILA, 2003-2024
본 데이터베이스는 크리에이티브 커먼즈 저작자표시-동일조건변경허락 4.0 국제 라이선스(CC BY-SA 4.0)에 따라 이용이 허가됩니다.
《瑜伽師地論》資料庫電子佛典製作與應用之研究 Yogācārabhūmi Database:A study on Creation and Application of Electronic Buddhist Texts
《유가사지론》(Yogācārabhūmi)은 인도 대승불교 유가행파(瑜伽行派)와 중국 법상종(法相宗)의 연원이며, 현장(玄奘)이 서역으로 경전을 구하러 간 동기이기도 합니다. 내용은 요가 수행자(선승)의 수행 단계와 경지에 관한 백과사전입니다.
본 데이터베이스는 TEI 태그셋(tag sets)을 사용하여 《유가사지론》의 이역본, 주석서, 산스크리트어 원전, 티베트어 번역본 등 전자 자료를 마크업(markup)하고, 그 구조적 특징(structural features)을 상호 참조(cross-reference) 표시하여 서로 대조할 수 있도록 하였습니다.
내용 설명 「내용 약어 및 약호」를 참고하십시오.
인터페이스 기능 「대조 열람 인터페이스」, 「전체 텍스트 검색」, 「해제(解題)」, 「다운로드」 및 「인용 복사」 등의 기능을 제공합니다.
북경여시인공지능기술연구원이 주도하고 항저우 영은사가 협력하는 ‘경산장 디지털화 프로젝트’는 첨단 인공지능 기술을 활용하여, 수록 경전의 양과 내용적 가치가 독보적인 한문 불교 대장경 《경산장》을 디지털 형태로 구축함으로써 학술적 활용을 증진하고 귀중한 문화유산을 보존하는 것을 목표로 합니다. 2018년 기술 연구를 시작으로 2020년 본격 착수된 이 프로젝트는 《경산장》 원본의 체계적인 분할, 교열, 형식 표점 등의 디지털화 단계를 거쳐 2025년 2월 최종 완료될 예정이며, 고문헌의 현대적 계승과 연구에 크게 기여할 것으로 기대됩니다.
바로: 4종의 다른 판본에서의 실제 글자를 살펴볼 수 있게 함. 실제 해당 프로젝트의 핵심이 하나가 한자에 대한 처리임. 홈페이지 하단에 있는 【字图库】【原字字种】【牌记汇编】는 신청을 해야 공개가 되는 기능들인데… 군침을 흘리고 싶은 한자 이미지 데이터셋이라는 것-0-!
프로젝트 배경 및 의의
중화민족에게 현존하는 고문헌들은 우수한 전통문화를 담고 있으며, 무궁한 민족적 지혜를 응집하고 있는, 선조들이 우리에게 남긴 귀중한 정신적 유산입니다. 문명을 계승하는 것은 시대가 우리에게 부여한 마땅히 짊어져야 할 책임입니다.
불교가 중국에 전래된 지 이미 이천 년이 흘렀습니다. 이천 년간의 교류와 융합을 통해 불교는 이미 중화의 우수한 전통문화에서 중요한 부분을 차지하게 되었습니다. 한문 불교 대장경은 한역 불교 경전의 총서로서, 산스크리트어에서 번역된 경(經)·율(律)·론(論) 삼장(三藏)과 역대 조사(祖師)와 대덕(大德)들의 주석서, 역사 전기, 경전 목록, 음의(音義), 선종 어록 등의 내용을 포함하며, 일정한 목록 체계에 따라 편집되었습니다. 현재 전해지는 대장경은 20여 종의 판본이 있으며, 수록된 경전 총수는 약 4,200여 종, 23,000여 권에 달하여, 광대하고 심오한 불교 사상과 수행 체계를 담고 있습니다.
대장경은 불교 연구에 있어 무궁무진한 자료의 보고일 뿐만 아니라, 철학, 역사, 문학 및 예술, 언어, 천문, 의약, 건축 등 다양한 학문 분야에도 매우 귀중하고 풍부한 자료를 제공합니다. 이는 고대 세계 문화의 소중한 유산이자 중화 문명이 세계 문화에 기여한 바입니다.
따라서 대장경을 보호하고 전승하며, 옛 성현들의 지혜에서 자양분을 얻고, 우수한 전통문화 속에서 자긍심을 찾는 것은 시대가 부여한 사명이며, 중화 문화가 끊임없이 이어지고 번성하는 원동력입니다.
지난 세기 90년대 이래 컴퓨터와 인터넷 기술의 발전에 따라 전 세계적으로 불교 경전 전자화 열풍이 불었습니다. 미국, 일본, 한국, 중국 대만 등의 국가와 지역에서 여러 불경 전자화 프로젝트가 시작되었으며, 그중 널리 사용되는 것은 대만 중화전자불전협회(CBETA)에서 제작한 불경 데이터베이스일 것입니다.
인공지능 등 디지털 기술의 급속한 발전은 불경 정리에 더욱 편리한 수단과 방법을 제공하는 동시에, 더 높은 요구와 도전 과제를 제시하고 있습니다. 이러한 시대적 배경 하에, 북경여시인공지능기술연구원(北京如是人工智能技术研究院, 이하 여시연구원)은 “디지털 고문헌으로 경전을 계승한다”는 취지 아래, 첨단 인공지능 등 디지털 기술을 응용하여 대장경 등 고문헌 경전을 정리하고 문명의 보호와 전승에 기여하고자 합니다.
2020년 4월, 여시연구원은 대장경 디지털화 프로젝트를 발족했습니다. 2024년 2월, 대장경 디지털화 프로젝트는 항저우 영은사(杭州灵隐寺)의 적극적인 지원을 받게 되었으며, 양측은 이 프로젝트를 협력하여 진행하기로 결정했습니다.
경산장 소개
《경산장》(径山藏)은 중국에 현존하는 한문 불교 대장경 중 가장 많은 경전을 수록한 것으로, 명나라 말기부터 청나라 중기까지 200여 년에 걸쳐 간행되었습니다. 여기에는 명청 시기 선승들의 어록이 대량으로 수록되어 있어 다른 한문 대장경에 비해 독특하고 심오한 가치를 지닙니다.
첫째, 장정(裝幀) 형식에서 《경산장》은 역대 대장경의 경접장(經摺裝)이나 권축장(卷軸裝) 방식을 벗어나 방책선장(方冊線裝)으로 바꾸었습니다. 이 새로운 장정 방식은 제작이 간단하고 휴대가 편리하여 대장경의 출판과 유통을 크게 촉진시켰으며, 이후 불교 경전의 출판 유통에 지대한 영향을 미쳤습니다.
둘째, 《경산장》은 중국에서 지금까지 불교 경전 수록량이 가장 많은 한문 대장경입니다. 현재까지 수집된 경전 수량만으로도 총 2,656종, 약 13,000권에 달하며, 이는 다른 한문 대장경이 따라올 수 없는 숫자입니다. 《경산장》에 처음으로 수록된 불경은 500여 부에 달하며, 다른 대장경에 전혀 수록되지 않은 저작도 300부를 넘어, 중국 불교 사료의 보고라 할 수 있습니다.
셋째, 《경산장》에는 송원(宋元) 이래로 수록된 대승 및 소승의 경율론 외에도, 중국 역대 고승들의 저술, 즉 주석, 문집, 전기, 잡록 등이 대거 포함되어 있으며, 역사, 문학, 철학 및 지방 고사 등에 관한 저작들도 함께 수록되어 있습니다. 그 내용은 광범위하고 풍부하여 중국 불교사, 철학사, 문학사 나아가 역대 선승들의 전기 연구에 중요한 사료가 되며, 중국 문화 연구에도 중요한 참고 자료로서 국내외 불교 연구자들로부터 “제2의 불교 사료 보고”, 명청 선종사 연구의 “돈황 발견”으로 불립니다.
넷째, 《경산장》은 대부분 권말에 패기(牌記)를 첨부하고 있어 연구 가치가 매우 높습니다. 이 패기들의 내용은 상당히 풍부하여, 장경 간행에 관한 대량의 정보를 포함할 뿐만 아니라, 당시의 역사, 철학, 경제, 문화 등 다양한 방면의 풍부한 문헌 자료를 제공합니다. 구체적으로 패기 내용은 기부자의 성명, 관직, 소재지, 기부 이유와 기부 은량 액수, 간행된 경전명, 권차, 자수와 판본 수량, 사경(寫經) 및 각수(刻手) 장인의 성명, 간행 시간과 장소 등을 포함합니다. 이러한 패기 정보는 해당 장경의 간행 상황을 이해하고, 명나라 말기부터 청나라 중기까지의 출판사, 사회 경제 상황, 사회 문화 등을 연구하는 데 풍부하고 귀중한 자료를 제공합니다.
1981년, 대만 신문풍출판사(新文丰出版社)에서 《명판가흥대장경》(明版嘉兴大藏经)을 영인 출판했습니다. 2008년, 민족출판사(民族出版社)에서 《가흥장》(嘉兴藏)을 영인 출판했습니다. 2016년, 국가도서관출판사(国家图书馆出版社)에서 《경산장》(径山藏)을 영인 출판했습니다. 본 웹사이트에서 사용된 이미지는 2016년 국가도서관출판사에서 출판한 《경산장》을 저본으로 하고 있습니다.
프로젝트 경과
2018년 9월: 대장경 고문헌 대상 인공지능 OCR 기술 및 고문헌 디지털화 생산 플랫폼 연구 개발 시작.
2020년 4월: “여시고적지대장경디지털화공정”(如是古籍之大藏经数字化工程) 발족 및 《경산장》 디지털화 프로젝트 착수.
2020년 5월: 《경산장》 분할 및 교열(切分校对) 시작.
2020년 8월: 《분할 및 교열 규범 v1.0》(切分校对体例v1.0) 발표.
2020년 11월: 《분할 및 교열 규범 v2.0》(切分校对体例v2.0) 발표, 규범 완성.
2021년 8월: 《경산장》 분할 및 교열 완료.
2021년 8월: 《문자 교열 규범 v1.0》(文字校对体例v1.0) 발표.
2021년 9월: 《경산장》 문자 교열 시작. 군집 교열(聚类校对) 방식, 원자 교열(原字校对) 원칙 채택. 관련 내용은 논문 《군집 교열과 간이 문자 생성(轻造字)에 기반한 고문헌 디지털화 방법과 실제》(基于聚类校对和轻造字的古籍数字化方法与实践) 참고.
2023년 5월: 《경산장》 형식 표점(格式标注) 시작.
2024년 2월: 대장경 디지털화 프로젝트가 항저우 영은사의 적극적인 지원을 받게 되어, 양측이 협력하여 이 프로젝트를 진행하기로 결정.
2024년 2월: 《경산장》 원자 교열 완료.
2024년 7월: 《경산장》 형식 표점 완료 (예정).
2025년 2월: 《경산장》 문자 검토 및 교정(文字检校) 등 마무리 작업 완료 (예정).
CBETA Semantic Searchbeta는 CBETA를 운영하는 타이완 법고불교학원에서 만든 시맨틱 검색 서비스이다. 시맨틱 검색 시스템은 키워드 검색이 아닌 문장형식의 질문에 대해서 그 의미와 가장 유사한 내용을 찾아주는 서비스로, 현재는 CBETA 데이터를 토대로 ChatGPT API를 활용하고 있다고 한다. 기본은 번체자 중국어 웹페이지이고, 간체자와 영어 웹페이지도 지원하는데, ChatGPT API가 당연히 다국어를 지원하기에 질문은 한국어로 해도 무방하다.
바로: 불경 기반 데이터셋에 “달빛과 관련된 사랑 이야기”를 물어보는 인간이 여기 있습니다. 음하하하-0-!! 참고로 아직은 많이 느립니다. -0-!!! 공식적인 안내로도 2분 정도가 걸린다고 하고, 체감은 그것보다 느립니다. “本功能透過 OpenAI API 製作,執行時間需100-120秒,請耐心等候” 아마도 Time Out으로 결과값이 아예 나오지 않는 경우도 있고요. -0-!
바로: 대략적인 시맨틱 데이터 검색 구현 방법입니다. 불경 데이터셋인 CBETA 데이터를 백터로 치환하고, 이를 토대로 사용자 질문에 대해서 Elastic Search로 유사 문건을 찾아주며, 최종적으로 개요와 관련성을 ChatGPT API를 통해서 판단하는 형식입니다. 응? 그냥 Elastic Search로 유사 문건을 찾아주면 안되냐라고 할텐데… 현 시점에서는 Elastic Search만으로는 충분히 괜찮다고 생각할만한 결과가 나오지 않는다고 하고, ChatGPT API 활용도 비용문제 등을 고려하여 로컬로 전환할 예정이라고 합니다.
바로: 저도 2020년쯤에 Sentence Tranformers로 다양한 데이터를 대상으로 시맨틱 검색을 구현했던 적이 있었는데, 나름 재미 있는 결과가 나오긴 하는데 결과가 조금 만족스럽지 않아서 던져 버렸던 기억이 나는군요. 그 동안 무려!! 5년이나 지났으니, 지금의 언어모델과 알고리즘으로는 더 좋은 결과가 나오지 않을까 기대하면서… 한번 구현해봐야겠군요. 뭐부터 해볼까나~~
CBETA Online now offers a public beta of its experimental feature Semantic Search!
Developed by the Dharma Drum Institute of Liberal Arts using OpenAI API and Retrieval Augmented Generation (RAG) technology, this marks the team’s first attempt to integrate generative AI into the CBETA database.
Unlike traditional keyword search, one simply enters a question or topic. The engine compares the topic to vectorised CBETA texts, retrieves the most relevant passages, and generates an overview with references and follow-up questions. Text references are also ranked by relevance and link directly to the texts in CBETA Online.
Try searching (Chinese input and output):
• 請問龍樹菩薩大約是在佛教哪個時期 (When did Nāgārjuna live)
• 找出與月亮和兔子相關的故事 (Stories that link the moon and a rabbit)
• 佛陀有教人如何瘦身或增進健康嗎 (Did the Buddha teach ways to lose weight or become healthier)
• 如何修行佛法獲得解脫 (How to practise Dharma for liberation)
At the moment one may filter by thematic groups (e.g., Āgama, Vinaya), with more options—canons, series, and beyond—planned soon. See Quick Guide below for details.
We invite you to explore this feature and would love to hear from you!
P.S.: For a deeper dive, join us online on Thursday, May 22 for the 2025 Spring Showcase of Dharma Drum Digital Archive Projects (法鼓數典專案春季成果發表會). Prof. Jenjou Hung, CBETA CEO, will share firsthand updates on this experiment and its future roadmap.
The “Graphs and Ontologies for Literary Evolution Models” (GOLEM) is a 5-year (2023-2027) research project funded by the European Commission (ERC StG). The GOLEM project models how narratives adapt across languages and cultures by developing an ontology that represents narratives independently of specific domains. To achieve this, GOLEM establishes a framework that defines the interrelationships among key narrative elements, such as characters, social relationships, and events. By employing ontology modeling, GOLEM offers a level of abstraction that facilitates the comparison of different stories, leading to a deeper understanding of narrative structures. In alignment with Linked Open Data principles, GOLEM is developed as an extension of CIDOC-CRM and LRMoo, two ontologies for cultural heritage, while aligning with the foundational ontology DOLCE-Lite-Plus (DLP).
Data
The current dataset for the GOLEM knowledge graph is based on fanfiction collected from Archive of Our Own (AO3), selected for its accessibility and comprehensive metadata system (Pannach et al., 2024a). Planned expansions in the future include narratives from other domains, such as folklore.
The GOLEM-UI search perspectives include four distinct views into the knowledge graph:
Metadata View: Overview of the associated metadata.
Fandoms View: Statistics on fandoms and associated stories.
Character View: A closer look into characters and their various romantic pairings, with a special focus on the Harry Potter fandom (Potterverse).
Literary Quality View: Statistics on readability and literary quality of the stories.
For more information about the knowledge graph and search interface, see our paper (Pannach et al., 2024b).
For more information about the ontology, visit the Golem GitHub, the Wiki, and the pyLODE-generated web page.
“문학 진화 모델을 위한 그래프 및 온톨로지”(GOLEM)는 유럽 집행위원회(ERC StG)가 자금을 지원하는 5년(2023-2027년) 연구 프로젝트입니다. GOLEM 프로젝트는 특정 분야에 독립적으로 서사를 표현하는 온톨로지를 개발하여, 서사가 여러 언어와 문화에 걸쳐 어떻게 변용되는지를 모델링합니다. 이를 위해 GOLEM은 등장인물, 사회적 관계, 사건과 같은 주요 서사 요소 간의 상호관계를 정의하는 프레임워크를 구축합니다. 온톨로지 모델링을 통해 GOLEM은 다양한 이야기를 비교하는 것을 용이하게 하는 추상화 수준을 제공하며, 이는 서사 구조에 대한 더 깊은 이해로 이어집니다. 링크드 오픈 데이터 원칙에 따라 GOLEM은 문화유산을 위한 두 가지 온톨로지인 CIDOC-CRM과 LRMoo의 확장으로 개발되며, 동시에 기초 온톨로지인 DOLCE-Lite-Plus(DLP)와 연계됩니다.
데이터
GOLEM 지식 그래프의 현재 데이터셋은 접근성과 포괄적인 메타데이터 시스템으로 인해 선택된 Archive of Our Own(AO3)에서 수집된 팬픽션을 기반으로 합니다 (Pannach 등, 2024a). 향후 계획된 확장에는 민담과 같은 다른 영역의 서사가 포함될 예정입니다.
GOLEM-UI 검색 관점은 지식 그래프에 대한 네 가지 개별 뷰를 포함합니다:
메타데이터 뷰: 연관된 메타데이터 개요.
팬덤 뷰: 팬덤 및 관련 이야기에 대한 통계.
캐릭터 뷰: 등장인물과 그들의 다양한 로맨틱 페어링에 대한 심층 분석, 특히 해리포터 팬덤(포터버스)에 중점을 둡니다.
문학적 품질 뷰: 이야기의 가독성 및 문학적 품질에 대한 통계.
지식 그래프 및 검색 인터페이스에 대한 자세한 내용은 저희 논문(Pannach 등, 2024b)을 참조하십시오.
GOLEM 지식 그래프 및 트리플 스토어를 위한 SPARQL 엔드포인트에 접속하십시오.
온톨로지에 대한 자세한 정보는 Golem GitHub, Wiki 및 pyLODE로 생성된 웹 페이지를 방문하십시오.
누리IDT 고문헌 한자 시스템은 고문헌 한자에 특화된 문자 인식 AI 모델을 사용하여 한자 텍스트를 추출합니다. 또한, 인공지능을 이용하여 문자를 추출하고 디지털 텍스트로 변환하는 고문헌 OCR 서비스를 제공합니다. 이 서비스는 띄어쓰기가 없는 고문헌 한문을 의미적으로 분절하여 표점을 찍어줌으로써 문맥을 쉽게 파악할 수 있도록 도와줍니다.
자동표점과 자동번역은 제약이 있기는 하지만 무료로 사용 가능합니다. 다만, OCR은 구매를 하셔야 하며, 상당한 액수입니다.
바로: 현재 심심풀이?!로 자동표점과 객체명식별을 테스트 하고 있는데… OCR 모듈부터 구현해서 무료로 풀면… 영업 방해…?!;;
▲『한국한자어사전(1996)』 ▲『이두사전(2020)』 ▲『한국한자자전(2023)』을 집대성해 온라인으로 서비스할 수 있도록 구성한 통합 검색 플랫폼
『한국한자어사전』과 『한국한자자전』에 수록된 한국식 한자 표제어 85,000여 개와 용례 74,000여 개, 『이두사전』의 이두어휘 약 4,200여 개와 이두용례 12,000여 개를 포함하고 있어 국내 최대의 한국한자 관련 데이터를 수록
기존 한자 유니코드에 등재되지 않거나 폰트가 없는 약 2,300자의 신출 한자는 단국대가 자체 개발한 ‘DK한국한자’ 폰트를 통해 구현해 자료의 완성도를 높였다.
『한국한자어사전』은 한국 고유의 한자 및 한자어를 수집 정리하여 체계적으로 정리한 공구서이다. 1978년 단국대학교 동양학연구원에서 『한한대사전』 편찬의 일환으로 시작한 이 사업은 1992년 1권을 간행한 이래 1996년 총 4권으로 완간하였는데, 총 4,550여 면, 표제자 5,174자, 한자어 89,705단어가 수록되었다.
그러나 웹서비스의 특성상 본 서비스에서는 표제자 548자, 한자어 80,657 단어를 제시하였다.
이 사전이 다른 한자 사전과 다른 점은 『삼국사기』를 비롯한 150여 종, 총 3,500여 책의 우리나라 고문헌에서 우리 고유의 한자 및 한자어 자료만을 채록하여 수록하였다는 점이다. 특히 『한국한자어사전』이 이전 사전과 차별되는 중요한 점 하나가 각 한자어의 용례를 볼 수 있는 전거 출전과 예문을 제시했다는 것이다. 극히 일부 특수한 경우를 제외하고는 대부분 전거를 제시하였다.
『한국한자자전』은 1996년 단국대학교 동양학연구원에서 간행한 『한국한자어사전』을 계승하여 자형, 자음, 자의 면에서 한국 고유의 특징을 지닌 한자를 모은 자전이다.
본 서비스를 통해 표제자 3,724자, 표제자 용례 5,626개를 제시하였다.
『이두사전』은 『한국한자어사전』 속에 들어 있는 이두 항목을 기초 자료로 하고, 현재까지 알려진 이두 자료 전체를 대상으로 이두를 채록하여 우리나라 이두를 집대성하여 정리한 사전이다.
이두는 삼국시대부터 20세기 초기에 이르기까지 한국에서 문자 생활의 수단이었다. 훈민정음 창제 이전에 이두는 우리의 역사와 문화를 기록하는 중요한 수단의 하나였다. 훈민정음 창제 이후에도 관공서의 행정을 처리하기 위한 중요한 기록 수단이었으며, 민간에서도 경제 활동 등 사회 활동을 위한 기록 수단이었다. 이러한 까닭에 이두를 사용하여 기록된 자료에는 우리의 근원적인 역사와 문화 관련 정보가 담겨 있다.
우리의 『이두사전』에서는 이두를 구성한 형태소를 그 의미와 기능에 따라 체계적으로 파악한 다음, 이두의 독음과 현대어 풀이를 제시하였다. 가급적 지금까지 알려진 이두 자료 전체를 대상으로 『이두사전』의 표제 항목을 발굴하였고, 이두의 의미를 이해하는 데에 중요한 용례를 발굴하여 제시하였다.
Japanese classical books, namely classical texts of Japan, boast a long history spanning over 1,200 years. Their diversity and the large number of existing copies are rare worldwide.
The National Institute of Japanese Literature regularly holds “Various Japanese Books,” which is now accessible in cyberspace, offering exhibits that allow for an understanding of the fundamentals of bibliography of Japanese classical books.
Over the past few months we have been working on further improvements of our image annotation service IMMARKUS (available at immarkus.xmarkus.org). IMMARKUS now supports IIIF imports: this means that you can build collections of (and annotate) high-quality zoomable images of any content (drawings, paintings, maps, manuscripts, archival documents, printed books etc) from libraries, museums, or private github and other online collections on the fly. You can combine these, also with your own local image collections.
We have been testing and would like to ensure that collections that researchers in East Asian Studies prefer to use are set up to allow for the full use of their data: images and all metadata. Please send us your favorite online IIIF image collections or collections you would like to work with in the future. We will then compile these into a list of favorite collections in East Asian Studies on our wiki pages, noting what access they provide.
Some of the issues you may run into because image collections were not correctly set up for IIIF are already listed on our wiki (https://github.com/…/Troubleshooting-IIIF-Manifest-Imports). We expect to publish a full update of our wiki pages by the end of the month, and will add favorite collections as they come in.
I have added some images below that show how custom collections can be built with IMMARKUS from major collections in the field: the Library of Congress, the National Palace Museum, the Harvard-Yenching Library, the UC Berkeley digital collections, the Bibliothèque National de France (Gallica), etc.
I also added a preview of what is forthcoming in our next major update: annotation with AI to improve the selection of image elements in the annotation module.
바로: 한국어 프롬프트는 아직은 어려운듯 합니다. 세부 디테일 조정 좋습니다. 다만 5장의 사진으로 5인 가족 인형모음을 만들려니 리소스의 문제인지 다른 문제인지 잘 생성이 안되는군요. 재미 있긴 합니다. 조만간 3D 모형으로까지 만들면 실제 인형 굿즈도 충분히 제작 가능할듯 합니다.
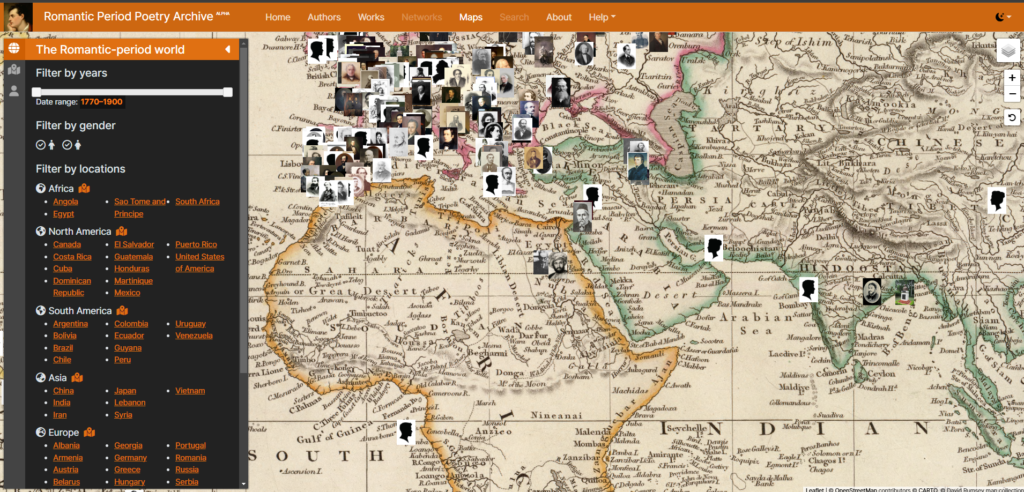
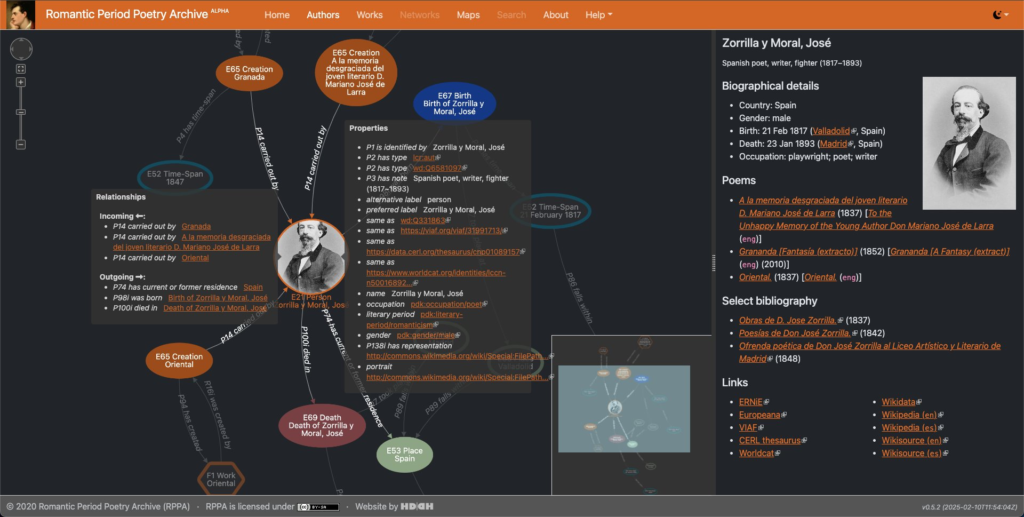
“[Deepl 번역] 낭만주의 시대 시 아카이브, 줄여서 RPPA [Listen]는 전 세계 낭만주의 시대 시의 새로운 오픈 액세스 디지털 플랫폼입니다. 여기서 글로벌이란 펠리시티 누스바움이 정의한 ‘글로벌 18세기’의 의미, 즉 영향과 수용보다는 대화와 교류가 지배적인 범주인 공간적, 개념적으로 확장된 패러다임입니다.2 RPPA는 시 전문 데이터베이스와 개방형 장학 플랫폼으로 구성되어 있습니다. 학술지 제작과 같은 전통적인 방식의 학술 연구 및 결과물과 컴퓨터 증강 분석, 시각화, 네트워크 분석, 지식 모델링 등과 같은 디지털 방식의 연구 및 출판을 모두 포용합니다.”
한국 최초의 네칸 만화인 ‘멍텅구리’가 조선일보 뉴스 라이브러리를 통해 100년 만에 다시 세상에 나왔습니다. KAIST 디지털인문사회과학부 전봉관 교수 연구팀(디지털인문사회과학부 석사과정 장우리, 문화기술대학원 석사졸업 이서준, 한국학중앙연구원 인문정보학 김병준 교수 포함)의 연구 성과로, 1924년부터 1933년까지 연재된 이 만화 전편(744편)이 이제 누구나 온라인으로 감상할 수 있습니다.
이번 프로젝트에서는 딥러닝 기술을 활용해 옛 신문에서 네칸 만화 객체를 자동으로 인식하고 추출하는 과정을 거쳤으며, 관련 연구는 지난 6월 디지털인문학 전문 국제저명학술지 Journal of Open Humanities Data에 게재되었습니다:
Lee, S., Kim, B., & Jun, B. G. (2024). Automatic Detection of Four-Panel Cartoon in Large-Scale Korean Digitized Newspapers using Deep Learning. https://doi.org/10.5334/johd.205
‘멍텅구리’는 단순한 오락만화 그 이상으로, 일제 강점기 총독부의 억압적 정책을 꼬집고 서양 문물을 소개하며, 당대의 사회 현실과 지식인들의 비판적 감각을 담고 있는 작품입니다. 노수현, 이상범 두 한국화 대가의 작품이기도 한 이 만화는 1920~30년대 조선 사회의 모습을 실감나게 전달합니다.